
सामग्री
स्रोत: Kran77 / ड्रीम्सटाईल.कॉम
टेकवे:
डीप लर्निंग मॉडेल्स संगणकावर स्वतःच विचार करण्यास शिकवत आहेत, ज्यामध्ये काही अतिशय मजेदार आणि मनोरंजक परिणाम आहेत.
जास्तीत जास्त डोमेन आणि उद्योगांवर सखोल शिक्षण लागू केले जात आहे. ड्रायव्हरलेस कार, गो प्ले, इमेज म्युझिक व्युत्पन्न करण्यापर्यंत, दररोज नवीन सखोल शिक्षण मॉडेल येत आहेत. येथे आम्ही अनेक लोकप्रिय खोल शिक्षण मॉडेल्सवर जाऊ. शास्त्रज्ञ आणि विकसक हे मॉडेल घेत आहेत आणि त्यांना नवीन आणि सर्जनशील मार्गाने सुधारित करीत आहेत. आम्हाला आशा आहे की हे शोकेस आपल्याला काय शक्य आहे ते पाहण्याची प्रेरणा देऊ शकेल. (कृत्रिम बुद्धिमत्तेच्या प्रगतीविषयी जाणून घेण्यासाठी, संगणक मानवी मेंदूचे अनुकरण करण्यास सक्षम असेल का?)
न्यूरल शैली
जेव्हा कोणालाही सॉफ्टवेअर गुणवत्तेची काळजी नसते तेव्हा आपण आपली प्रोग्रामिंग कौशल्ये सुधारू शकत नाही.
मज्जातंतू कथाकार

न्यूरल स्टोरीटेलर एक मॉडेल आहे जे जेव्हा एखादी प्रतिमा दिली जाते तेव्हा प्रतिमेबद्दलची एक प्रणय कथा निर्माण करू शकते. हे एक मजेदार खेळण्यासारखे आहे आणि तरीही आपण भविष्याची कल्पना करू शकता आणि ही सर्व कृत्रिम बुद्धिमत्ता मॉडेल्स कोणत्या दिशेने जात आहेत हे पाहू शकता.

वरील कार्य म्हणजे "स्टाईल-शिफ्टिंग" ऑपरेशन जे मॉडेलला कादंबर्यामधून कथा शैलीमध्ये मानक प्रतिमा मथळे हस्तांतरित करण्यास अनुमती देते. स्टाईल शिफ्टिंगला "ए न्यूरल अल्गोरिदम ऑफ आर्टिस्टिक स्टाईल" प्रेरणा मिळाली.
डेटा
या मॉडेलमध्ये वापरल्या जाणार्या डेटाचे दोन मुख्य स्त्रोत आहेत. एमएससीसीओ मायक्रोसॉफ्टचे एक डेटासेट आहे ज्यात सुमारे 300,000 प्रतिमा आहेत, ज्यात प्रत्येक प्रतिमा पाच मथळे आहेत. एमएससीसीओ हा फक्त एक पर्यवेक्षी डेटा वापरला जात आहे, म्हणजेच हा एकच डेटा आहे जिथे मानवांना आत जावे आणि प्रत्येक प्रतिमेसाठी स्पष्टपणे मथळे लिहायचा.
फीड-फॉरवर्ड न्यूरल नेटवर्कची एक मुख्य मर्यादा म्हणजे त्याला मेमरी नाही. प्रत्येक अंदाज मागील गणितांपासून स्वतंत्र आहे, जणू नेटवर्कने आतापर्यंत केलेला पहिला आणि एकमेव अंदाज आहे. परंतु वाक्यांशाचे किंवा परिच्छेदाचे भाषांतर करणे यासारख्या बर्याच कामांसाठी, इनपुटमध्ये अनुक्रमिक आणि अनुरुप संबंधित डेटा असणे आवश्यक आहे. उदाहरणार्थ, आजूबाजूच्या शब्दांद्वारे दिलेली फसवणूक न करता वाक्यातल्या एका शब्दाचा अर्थ काढणे कठीण होईल.
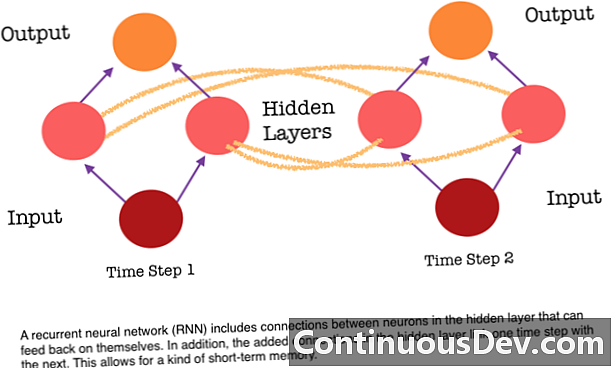
आरएनएन भिन्न आहेत कारण ते न्यूरॉन्स दरम्यान कनेक्शनचा दुसरा सेट जोडतात. हे दुवे अनुक्रमातील पुढच्या टप्प्यावर लपलेल्या थरातील न्यूरॉन्समधून केलेल्या क्रियाकलापांना स्वत: मध्ये परत खाद्य देतात. दुस words्या शब्दांत, प्रत्येक टप्प्यावर, लपलेल्या लेयरला खाली असलेल्या स्तरातून आणि अनुक्रमातील मागील चरणातून दोन्ही सक्रियकरण प्राप्त होते. ही रचना अनिवार्यपणे वारंवार न्यूरल नेटवर्क मेमरी देते. तर ऑब्जेक्ट शोधण्याच्या कार्यासाठी, आरएनएन सध्याची प्रतिमा कुत्रा आहे की नाही हे निर्धारीत करण्यासाठी कुत्र्यांच्या मागील वर्गीकरणावरून काढू शकते.
चार-आरएनएन टेड
लपलेल्या थरामधील ही लवचिक रचना वर्ण-स्तराच्या भाषेच्या मॉडेलसाठी आरएनएनला खूप चांगली बनविण्यास परवानगी देते. चार आरएनएन, मूळत: आंद्रेज कर्पथी यांनी तयार केलेला एक मॉडेल आहे जो एक फाईल इनपुट म्हणून घेते आणि अनुक्रमे पुढील वर्णांची भविष्यवाणी करण्यास शिकण्यासाठी आरएनएनला प्रशिक्षण देते. आरएनएन वर्णानुसार वर्ण तयार करू शकते जे मूळ प्रशिक्षण डेटासारखे दिसेल. विविध टीईडी वार्ताहरांच्या प्रतिलेखांचा वापर करून डेमो प्रशिक्षण दिले गेले आहे. मॉडेलला एक किंवा अनेक कीवर्ड फीड करा आणि ते टीईडी टॉकच्या व्हॉईस / शैलीमध्ये कीवर्ड (से) बद्दल एक उतारा तयार करेल.
निष्कर्ष
हे मॉडेल मशीन बुद्धिमत्तेत नवीन प्रगती दर्शविते जे खोल शिक्षणामुळे शक्य झाले आहेत. सखोल शिक्षण हे दर्शवितो की आपण अशा समस्यांचे निराकरण करू शकतो ज्या आपण यापूर्वी कधीही सोडवू शकत नव्हता आणि आपण अद्याप त्या पठारावर पोहोचलो नाही. पुढील काही वर्षांत ड्रायव्हरलेस कारसारख्या आणखी ब exciting्याच रोमांचक गोष्टी पाहण्याची अपेक्षा.