टेकवे: होस्ट रेबेका जोझवियाक यांनी डेटा आर्किटेक्चर सोल्यूशन्स विषयी एरिक लिटल ऑफ ओस्थूस, फर्स्ट सॅन फ्रान्सिस्को पार्टनरचे मालकॉम चिशोल्म आणि आयडेराच्या रॉन हुईझेंगा यांच्याशी चर्चा केली.
आपण सध्या लॉग इन केलेले नाही. कृपया व्हिडिओ पाहण्यासाठी लॉग-इन किंवा साइन-अप करा.
रेबेका जोझवियाक: महोदयांनो, हॅलो आणि २०१ 2016 च्या हॉट टेक्नॉलॉजीजमध्ये आपले स्वागत आहे. आज आम्ही “बिझिनेस-ड्राईव्ह डेटा आर्किटेक्चर बनविणे” नक्कीच चर्चेचा विषय बोलत आहोत. माझे नाव रेबेका जोझवियाक आहे, मी आजच्या वेबकास्टसाठी आपले होस्ट होईन. आम्ही # हॉटटेक १ of च्या हॅशटॅगसह ट्वीट करतो जेणेकरुन आपण आधीपासून असाल तर कृपया त्यातही सामील होण्यास मोकळ्या मनाने. आपल्याकडे कोणत्याही वेळी प्रश्न असल्यास, कृपया आपल्या स्क्रीनच्या तळाशी उजवीकडे असलेल्या प्रश्नोत्तर फलकात त्यांना द्या आणि आम्ही खात्री करुन देऊ की त्यांचे उत्तर मिळाले आहे. तसे नसल्यास आम्ही आमच्या अतिथींनी ते आपल्यासाठी मिळवल्याची खात्री आम्ही करू.
तर आज आम्हाला खरोखरच एक आकर्षक ओळ मिळाली आहे. आज आमच्याबरोबर बरीच भारी हिटर्स आहेत. आमच्याकडे ओस्टस कडील डेटा सायन्सचे एपी लिटिल, व्हीपी आहेत. आमच्याकडे फर्स्ट सॅन फ्रान्सिस्को पार्टनर्ससाठी मुख्य अभिनव अधिकारी माल्कम चिशोल्म आहेत जे खरोखरच छान शीर्षक आहे. आणि आमच्याकडे IDERA चे वरिष्ठ उत्पादन व्यवस्थापक रॉन Huizenga आहे. आणि, आपल्याला माहितीच आहे की डेटा व्यवस्थापन आणि मॉडेलिंग सोल्यूशन्सचा IDERA खरोखर एक पूर्ण संच आहे. आणि आज तो आपल्याला त्याचे समाधान कसे कार्य करते याबद्दल एक डेमो देणार आहे. एरिक लिटलपर्यंत आम्ही पोहोचण्यापूर्वी मी तो बॉल तुमच्याकडे देत आहे.
एरिक लिटल: ठीक आहे, खूप खूप आभार. तर मी येथे दोन विषयांवर जात आहे, असे मला वाटते की रॉन यांच्या चर्चेशी थोडासा संबंध आहे आणि आशा आहे की या विषयांपैकी काही प्रश्न व उत्तर दिले जाईल.
म्हणून आयडीआरएच्या कार्यात मला रस घेणारी गोष्ट ही आहे की मला वाटते की जटिल वातावरण खरोखरच आजकाल बरेच व्यवसाय मूल्ये चालवित आहेत. आणि जटिल वातावरणाद्वारे आपला अर्थ जटिल डेटा वातावरण आहे. आणि तंत्रज्ञान खरोखर वेगाने पुढे जात आहे आणि आजच्या व्यवसाय वातावरणात ठेवणे कठीण आहे. म्हणून जे लोक तंत्रज्ञानाच्या जागांवर काम करतात त्यांना बर्याचदा असे दिसेल की आपल्याकडे असे ग्राहक आहेत जे यासह समस्या सोडवत आहेत, “मी मोठा डेटा कसा वापरू? मी शब्दार्थ कसे समाविष्ट करू? मी या नवीन गोष्टींपैकी काही माझ्या जुन्या डेटाशी कसा जोडाल? "आणि असं, आणि या प्रकारामुळे आजकाल आपल्याला या चार वीरेंद्र मोठ्या डेटामध्ये घेऊन जाते ज्याच्याशी बरेच लोक परिचित आहेत आणि मला समजते की तेथे चारपेक्षा जास्त असू शकतात. कधीकधी - मी साधारण आठ किंवा नऊ पाहिले आहेत - परंतु सामान्यत: जेव्हा लोक मोठ्या डेटासारख्या गोष्टींबद्दल बोलतात किंवा आपण मोठ्या डेटाबद्दल बोलत असाल तर आपण सहसा अशा प्रकारचे काहीतरी पहात आहात जे एंटरप्राइझ स्केल आहे. आणि म्हणून लोक म्हणतील की ठीक आहे, आपल्या डेटाच्या व्हॉल्यूमबद्दल विचार करा, जे सामान्यत: लक्ष केंद्रित करते - आपल्याकडे इतकेच आहे. डेटाचा वेग मी एकतर किती वेगात फिरवू शकतो किंवा मी किती वेगवान क्वेरी करू शकतो किंवा उत्तरे मिळवू शकतो इत्यादींशी संबंधित आहे. आणि वैयक्तिकरित्या मला वाटते की त्या डाव्या बाजूला काहीतरी निराकरण केले जात आहे आणि बर्याच भिन्न पध्दतींनी तुलनेने द्रुतपणे हाताळले जात आहे. परंतु उजवीकडे मला सुधारण्याची क्षमता आणि बर्याच नवीन तंत्रज्ञान दिसतात जे खरोखर अग्रभागी येत आहेत. आणि त्याचा डेटा प्रकारातील तिसर्या स्तंभाशी खरोखर संबंध आहे.
तर दुस other्या शब्दांत, बहुतेक कंपन्या आजकाल संरचित, अर्ध-संरचित आणि अप्रचलित डेटाकडे पहात आहेत. प्रतिमा डेटा हा एक चर्चेचा विषय बनू लागला आहे, म्हणून संगणक दृष्टी वापरण्यात सक्षम असणे, पिक्सेल पहाणे, स्क्रॅप करणे सक्षम असणे, एनएलपी, अस्तित्व माहिती, आपल्याकडे ग्राफिक माहिती आहे जी एकतर सांख्यिकी मॉडेलमधून येते किंवा सिमेंटिक मॉडेलमधून येत आहे. , आपल्याकडे सारण्यांमध्ये अस्तित्त्वात असलेला रिलेशनल डेटा आहे वगैरे. आणि म्हणून हा सर्व डेटा एकत्रितपणे आणणे आणि हे सर्व भिन्न प्रकार खरोखर मोठ्या आव्हानाचे प्रतिनिधित्व करीत आहेत आणि आपल्याला गार्टनर आणि उद्योगातील ट्रेंडचे अनुसरण करणारे अन्य लोक हे आपल्याला दिसेल.
आणि मग लोक मोठ्या डेटाविषयी ज्या अंतिम गोष्टींबद्दल बोलतात ते म्हणजे बर्याचदा व्होरासिटीची ही कल्पना असते जी खरोखरच आपल्या डेटाची अनिश्चितता असते, त्यातील अस्पष्टता असते. आपला डेटा कशाबद्दल आहे हे आपल्याला किती चांगले माहित आहे, तिथे काय आहे हे आपल्याला कसे चांगले समजते आणि काय ते आपल्याला माहित आहे? आकडेवारी वापरण्याची क्षमता आणि आपल्याला कदाचित माहित असलेल्या किंवा काही कॉन वापरण्याची काही प्रकारच्या माहिती वापरण्याची क्षमता तेथे महत्त्वपूर्ण ठरू शकते. आणि म्हणून आपल्याकडे आपल्याकडे किती डेटा आहे त्यानुसार या डेटाकडे पाहण्याची क्षमता, आपल्यास आपल्याकडे इतक्या वेगाने फिरणे किंवा त्याकडे जाणे आवश्यक आहे, आपल्या एंटरप्राइझमधील डेटाचा सर्व प्रकार आणि आपण कोठे आहात याबद्दल आपण किती निश्चित आहात ते आहे, ते काय आहे, कोणत्या गुणवत्तेत आहे इत्यादी. यासाठी खरोखरच बर्याच व्यक्तींमध्ये त्यांचे डेटा प्रभावीपणे व्यवस्थापित करण्यासाठी मोठ्या प्रमाणात, समन्वित प्रयत्नांची आवश्यकता आहे. मॉडेलिंग डेटा, म्हणूनच आजच्या जगात महत्त्वपूर्ण आहे. म्हणून चांगले डेटा मॉडेल्स खरोखरच एंटरप्राइझ अनुप्रयोगांमध्ये बरेच यश मिळवित आहेत.
आपल्याकडे निरनिराळ्या स्त्रोतांमधून डेटा स्रोत आहेत जसे की आम्ही म्हणत होतो, ज्यांना खरोखरच वेगवेगळ्या प्रकारच्या समाकलनाची आवश्यकता आहे. म्हणून हे सर्व एकत्र खेचणे म्हणजे क्वेरी चालविण्यास सक्षम असणे, उदाहरणार्थ, असंख्य प्रकारच्या डेटा स्रोतांमध्ये आणि माहिती परत खेचणे खरोखर उपयुक्त आहे. परंतु हे करण्यासाठी आपल्याला चांगल्या मॅपिंग धोरणांची आवश्यकता आहे आणि म्हणून त्या प्रकारच्या डेटाचे मॅपिंग करणे आणि त्या मॅपिंग्ज ठेवणे खरोखर एक आव्हान असू शकते. आणि मग आपल्याकडे हा मुद्दा आहे, तसेच मी माझा वारसा डेटा या सर्व नवीन डेटा स्रोतांशी कसा जोडू? समजा मला आलेख मिळाला आहे, तर मी माझा सर्व रिलेशनशियल डेटा घेतो आणि त्यास ग्राफमध्ये ठेवतो? सहसा ही चांगली कल्पना नाही. तर हे कसे चालू आहे की लोक चालू असलेल्या या सर्व प्रकारच्या मॉडेल्सचे व्यवस्थापन करण्यास सक्षम आहेत? विश्लेषण या प्रकारच्या विविध प्रकारच्या डेटा स्रोत आणि संयोगांवर खरोखरच चालवावे लागते. तर यामधून जी उत्तरे येत आहेत, लोकांना खरोखर चांगले व्यवसाय निर्णय घेण्याची आवश्यकता आहे ही उत्तरे गंभीर आहेत.
हे केवळ तंत्रज्ञानाच्या फायद्यासाठी तंत्रज्ञानाचे बांधकाम करण्याबद्दल नाही, खरंच आहे, मी काय करणार आहे, मी त्यासह काय करू शकतो, मी कोणत्या प्रकारचे विश्लेषण चालवू शकेन आणि क्षमता, म्हणूनच, जसे मी आधीच केले आहे याबद्दल बोलत होतो, ही सामग्री एकत्र खेचण्यासाठी, समाकलित करणे खरोखरच खरोखर महत्वाचे आहे. आणि अशा प्रकारच्या विश्लेषणापैकी एक फेडरेशन शोध आणि क्वेरी यासारख्या गोष्टींवर चालते. ते खरोखरच आवश्यक बनले आहे. आपल्या क्वेरी सामान्यत: एकाधिक प्रकारच्या स्त्रोतांमध्ये थ्रेड केल्या पाहिजेत आणि विश्वासूमध्ये माहिती परत खेचणे आवश्यक आहे.
एक महत्त्वाचा घटक जो बर्याचदा, विशेषत: लोक अर्थशास्त्र तंत्रज्ञानासारख्या महत्वाच्या गोष्टींकडे पाहत असतात - आणि ही अशी एक गोष्ट आहे जी मी आशा करतो की रॉन आयडेरा दृष्टिकोनातून थोडा बोलत असेल - आपण कसे वेगळे किंवा व्यवस्थापित कराल डेटा डेटामधूनच आपल्या डेटाचे मॉडेल स्तर, त्या कच्च्या डेटापासून? डेटाबेस खाली डेटा थरात आपल्याकडे कागदजत्र डेटा असू शकतात, आपल्याकडे स्प्रेडशीट डेटा असू शकतो, आपल्याकडे प्रतिमा डेटा असू शकतो. आपण फार्मास्युटिकल उद्योगांसारख्या क्षेत्रात असल्यास आपल्याकडे वैज्ञानिक डेटा मोठ्या प्रमाणात मिळाला आहे. आणि मग या लोकांच्या सामान्यत: एखादा मॉडेल तयार करण्याचा मार्ग शोधतो ज्यामुळे तो डेटा द्रुतपणे समाकलित करू शकतो आणि जेव्हा आपण डेटा शोधत असता तेव्हा आपण मॉडेल थरात सर्व डेटा ओढण्याचा विचार करीत नाही. , आपण ज्या मॉडेल लेयरकडे पहात आहात त्या म्हणजे गोष्टी म्हणजे काय, सामान्य शब्दसंग्रह, सामान्य प्रकारची संस्था आणि नातेसंबंध आणि जेथे आहे त्या डेटामध्ये खरोखर पोहोचण्याची क्षमता याबद्दल एक छान तार्किक प्रतिनिधित्व देणे. तर ते काय आहे ते सांगावे लागेल आणि ते कोठे आहे ते सांगावे लागेल आणि ते कसे आणायचे आणि परत कसे आणायचे हे सांगणे आवश्यक आहे.
म्हणून हा दृष्टिकोन आहे जो अर्थपूर्ण तंत्रज्ञानाचा पुढे उपयोग करण्यास यशस्वी झाला आहे, जे असे क्षेत्र आहे जेथे मी खूप काम करतो. म्हणून मला एक प्रश्न जो रॉनसाठी विचारू इच्छित होता, आणि मला असे वाटते की प्रश्नोत्तर विभागातील उपयुक्त ठरेल, हे पहा की हे आयडीआरए प्लॅटफॉर्मद्वारे कसे पूर्ण झाले आहे? तर मॉडेल लेयर प्रत्यक्षात डेटा लेयरपेक्षा वेगळा आहे का? ते अधिक समाकलित आहेत? ते कसे कार्य करते आणि त्यांच्या जवळून पाहिले जाणारे काही परिणाम आणि फायदे काय आहेत? म्हणूनच संदर्भ डेटा खरोखरच गंभीर बनत आहे. म्हणून आपल्याकडे असे प्रकारचे डेटा मॉडेल्स असणार आहेत, जर आपण फेडरेशन तयार करण्यास आणि सर्व गोष्टी शोधण्यात सक्षम असाल तर आपल्याकडे खरोखर चांगला संदर्भ डेटा असणे आवश्यक आहे. पण समस्या संदर्भ डेटा राखण्यासाठी खरोखर कठीण असू शकते आहे. म्हणूनच बहुतेक वेळा स्वत: मध्येच मानकांची नावे ठेवणे एक कठीण आव्हान असते. एक गट काहीतरी एक्सला कॉल करेल आणि एका गटाला काहीतरी वाई कॉल करेल आणि आता आपल्यास अशी समस्या आहे की जेव्हा या प्रकारची माहिती शोधत आहेत तेव्हा कोणी एक्स आणि वाई कसे सापडेल? आपण त्यांना केवळ डेटाचा एक भाग देऊ इच्छित नसल्याने आपण त्यांना संबंधित सर्वकाही देऊ इच्छित आहात. त्याच वेळी अटी बदलतात, सॉफ्टवेअर नापसंत होते, आणि अशाच प्रकारे, आपण वेळोवेळी त्या संदर्भ डेटाची देखभाल आणि देखभाल कशी करता?
आणि पुन्हा, अर्थशास्त्र तंत्रज्ञानाने, विशेषत: वर्गीकरण आणि शब्दसंग्रह, डेटा शब्दकोष यासारख्या गोष्टींचा वापर करून, हे करण्याचा एक मानक स्थान प्रदान केला आहे, जो खरोखर अत्यंत मजबूत आहे, हे विशिष्ट प्रकारच्या मानकांचा उपयोग करते, परंतु डेटाबेस समुदायाने हे केले आहे बराच काळ तसेच, वेगवेगळ्या मार्गांनी. मला वाटते की इथली एक की कदाचित अस्तित्व-रिलेशन मॉडेल कसे वापरावे याबद्दल विचार करणे, कदाचित ग्राफचे मॉडेल कसे वापरावे किंवा येथे काही प्रकारचे दृष्टिकोन आपल्याला खरोखर आपला संदर्भ डेटा हाताळण्याचा एक मानक अंतराचा मार्ग देईल. आणि अर्थातच एकदा आपल्याकडे संदर्भ डेटा असल्यास, मॅपिंग धोरणांमध्ये विविध नावे आणि घटक व्यवस्थापित करावे लागतात. म्हणून विषय विषय तज्ञांना नेहमी त्यांच्या स्वत: च्या अटी वापरण्यास आवडते.
म्हणूनच हे नेहमीच एक आव्हान असते, आपण एखाद्यास माहिती कशी द्याल परंतु ते त्याविषयी ज्या पद्धतीने बोलतात त्यास त्यास संबद्ध करतात? एखाद्या समुहाकडे काहीतरी पाहण्याचा एक मार्ग असू शकतो, उदाहरणार्थ, आपण एखाद्या औषधावर काम करणारे केमिस्ट असू शकता आणि आपण त्याच औषधावर काम करणारे स्ट्रक्चरल बायोलॉजिस्ट असू शकता आणि आपल्याला एकाच प्रकारच्या घटकांसाठी भिन्न नावे असू शकतात आपल्या क्षेत्राशी संबंधित. आपल्याला ते वैयक्तिकृत शब्दावली एकत्र आणण्याचे मार्ग शोधणे आवश्यक आहे, कारण दुसरा दृष्टिकोन असा आहे की आपण लोकांना त्यांची मुदत ठेवण्यास भाग पाडले पाहिजे आणि दुसर्याची भाषा वापरली पाहिजे जी त्यांना बर्याचदा आवडत नाही. येथे आणखी एक मुद्दा म्हणजे मोठ्या संख्येने समानार्थी शब्द हाताळणे कठिण होते, म्हणून बर्याच लोकांच्या डेटामध्ये भिन्न शब्द आहेत जे समान गोष्टीचा संदर्भ घेऊ शकतात. एकाधिक-टू-वन रिलेशनशिपचा वापर करुन आपल्याला तेथे संदर्भाची समस्या आहे. वैशिष्ट्यीकृत अटी उद्योग ते उद्योगापेक्षा भिन्न असतात म्हणून आपण या प्रकारच्या डेटा व्यवस्थापनासाठी एखादे अतिरीक्त समाधान आणत असल्यास एका प्रकल्पातून किंवा एका अनुप्रयोगामधून ते किती सहज पोर्टेबल आहे? हे आणखी एक आव्हान असू शकते.
ऑटोमेशन महत्वाचे आहे आणि हे देखील एक आव्हान आहे. संदर्भ डेटा व्यक्तिचलितपणे हाताळणे महाग आहे. व्यक्तिचलित मॅपिंग ठेवणे महाग आहे आणि विषय तज्ञांनी त्यांचे रोज-रोजचे काम करणे थांबविणे आणि त्यात जाणे आवश्यक आहे आणि डेटा शब्दकोष आणि सतत अद्ययावत व्याख्या वगैरे निश्चित करणे वगैरे आहे. प्रतिकृती योग्य शब्दसंग्रह खरोखरच खूप मूल्य दर्शविते. तर अशा शब्दसंग्रह अनेकदा आपल्याला आपल्या संस्थेस बाह्य सापडतील. आपण कच्च्या तेलामध्ये काम करत असल्यास, उदाहरणार्थ अशा काही प्रकारच्या ओपन-सोर्स स्पेसमधून आपण औषधे घेऊ शकता, बँकिंग उद्योगासारखेच आणि आर्थिक अशा अनेक प्रकारच्या शब्दावली असतील. लोक तिथे पुन्हा वापरता येण्यासारख्या, सर्वसामान्य, प्रतिकृती असलेल्या शब्दसंग्रह ठेवत आहेत.
आणि पुन्हा, आयडीआरए टूलकडे पहात असताना, मी हे पाहण्याची उत्सुकता आहे की ते कोणत्या प्रकारचे मानक वापरण्याच्या बाबतीत हे कसे हाताळतात. शब्दांकाच्या जगात आपण अनेकदा एसकेओएस मॉडेल्ससारख्या गोष्टी पाहता जे संबंधांपेक्षा कमीतकमी विस्तृत / संकुचित मानदंड प्रदान करतात आणि त्या गोष्टी ईआर मॉडेल्समध्ये करणे कठीण असू शकते परंतु, आपल्याला माहित आहे, अशक्य नाही, हे त्यातील किती गोष्टीवर अवलंबून आहे यंत्रणा आणि ती दुवा जो आपण त्या प्रकारच्या सिस्टममध्ये हाताळू शकता.
म्हणून शेवटी मला फक्त इंडस्ट्रीत दिसणा to्या काही सिमेंटिक इंजिनांची तुलना करण्याची इच्छा होती आणि कोणत्या प्रकारचे सिमेंटीक तंत्रज्ञानाच्या सहाय्याने IDERA ची यंत्रणा कशी वापरली गेली आहे याविषयी बोलण्यासाठी एक प्रकारचा रॉन आणि प्राइम यांना विचारण्यास सांगा.हे ट्रिपल स्टोअर, आलेख डेटाबेससह समाकलित करण्यास सक्षम आहे? बाह्य स्त्रोत वापरणे किती सोपे आहे कारण स्पॅन्क्युअल एंडपॉईंट्स वापरुन अर्थपूर्ण जगात अशा प्रकारच्या गोष्टी बर्याचदा कर्ज घेतल्या जाऊ शकतात? आपण थेट आपल्या मॉडेलमध्ये आरडीएफ किंवा ओडब्ल्यूएल मॉडेल आयात करू शकता - त्यांचा पुन्हा संदर्भ घ्या - म्हणून, उदाहरणार्थ, जीन ऑन्टोलॉजी किंवा प्रथिने ऑन्टोलॉजी, जे स्वतःच्या कारभाराच्या संरचनेसह स्वतःच्या जागेत कुठेही राहू शकतात आणि मी फक्त सर्व किंवा आयात करू शकतो त्याचा एक भाग म्हणजे मला माझ्या स्वत: च्या मॉडेल्समध्ये आवश्यक आहे. आणि IDERA या समस्येकडे कसे पोहोचते हे जाणून घेण्यास मी उत्सुक आहे. आपल्याला सर्वकाही अंतर्गतरित्या राखणे आवश्यक आहे, किंवा इतर प्रकारचे मानक मॉडेल वापरण्याचे आणि त्यात खेचण्याचे मार्ग आहेत आणि ते कसे कार्य करते? आणि शेवटची गोष्ट जी मी येथे नमूद केली ती म्हणजे शब्दावली आणि मेटाडेटा रेपॉजिटरी तयार करण्यासाठी खरोखर मॅन्युअल कामात किती सहभाग आहे?
म्हणून मला माहित आहे की या प्रकारच्या गोष्टींवर रॉन आम्हाला काही डेमो दर्शवित आहेत जे खरोखर मनोरंजक असेल. परंतु मी ग्राहकांशी सल्लामसलत करताना सहसा पहात असलेल्या समस्या म्हणजे लोक त्यांच्या स्वत: च्या परिभाषा किंवा स्वत: च्या मेटाडेटामध्ये लिहित असल्यास बर्याच त्रुटी उद्भवतात. तर आपल्याला चुकीचे स्पेलिंग्ज मिळतात, आपल्याकडे चरबी-बोटांच्या त्रुटी आढळतात, ही एक गोष्ट आहे. आपणास असे लोक देखील मिळतील जे तुम्हाला काही माहिती घेतील, विकिपीडिया किंवा एखादे स्त्रोत जे आपल्या परिभाषामध्ये आपल्याला पाहिजे असलेल्या गुणवत्तेचे आवश्यक नाही किंवा आपली व्याख्या केवळ एका व्यक्तीच्या दृष्टीकोनातून आहे म्हणून ती पूर्ण नाही, आणि नंतर ते स्पष्ट नाही प्रशासन प्रक्रिया कशी कार्य करते. जेव्हा आपण संदर्भ डेटाबद्दल बोलत असाल आणि कोणत्याही वेळी एखाद्याच्या मास्टर डेटामध्ये हे कसे बसू शकते, ते आपला मेटाडेटा कसा वापरणार आहेत याबद्दल आणि आपण जेव्हा बोलता तेव्हा शासन एक निश्चितच फार मोठी समस्या आहे. वगैरे.
तर मला फक्त यातील काही विषय येथे सांगायचे होते. या आयटम आहेत ज्या मी व्यवसायात बर्याच प्रकारच्या सल्लामसलत आणि बर्याच वेगवेगळ्या जागांवर पाहत आहोत, आणि यापैकी काही विषय दर्शविण्यासाठी रॉन आयडीईआरए आपल्याला काय दर्शवित आहे हे पाहण्यास मला खरोखर रस आहे. . तर आभारी आहे
रेबेका जोझवियाक: एरीक, खूप खूप धन्यवाद, आणि मला तुमची टिप्पणी खरोखर आवडली आहे की जर लोक त्यांच्या स्वत: च्या व्याख्या किंवा मेटाडेटा लिहित असतील तर बर्याच त्रुटी उद्भवू शकतात. मला माहित आहे की पत्रकारिताविश्वात असा मंत्र आहे की “बर्याच डोळ्यांमुळे काही चुका होतात,” पण जेव्हा व्यावहारिक अनुप्रयोगांचा विचार केला जाईल, तेव्हा बर्यापैकी हात कुकीजमध्ये तुटलेल्या कुकीज ठेवतात, बरोबर?
एरिक लिटल: होय आणि जंतू.
रेबेका जोझवियाक: हो त्यासह मी पुढे जात आहे आणि हे मालकॉम चिशोलमला पाठवणार आहे. मॅल्कम, मजला आपला आहे.
मॅल्कम चिशोलम: रेबेका, खूप खूप धन्यवाद. मी एरिक ज्याविषयी बोलत आहे त्याबद्दल थोडेसे पाहू इच्छितो, आणि काही निरीक्षणे जोडायच्या आहेत ज्या तुम्हाला माहितीय आहेत, “टॉवर्ड बिझिनेस-ड्राइव्हन डेटा आर्किटेक्चर” विषयी बोलताना रॉनलाही प्रतिसाद देणे आवडेल ”- व्यवसाय चालविण्याचा अर्थ काय आहे आणि ते महत्वाचे का आहे? किंवा हे केवळ काही प्रकारचे हायपे आहे? मला वाटत नाही की ते आहे.
१ 64 .64 च्या सुमारास - म्हणायचे की, आजपासून काय चालले आहे, हे आपल्याला माहित आहे की मेनफ्रेम संगणक खरोखरच कंपन्यांना उपलब्ध झाले आहेत, आपण पाहू शकता की त्यात बरेच बदल झाले आहेत. आणि हे बदल मी प्रक्रिया-केंद्रिततेपासून डेटा-केंद्रिततेकडे बदल म्हणून थोडक्यात सांगत होतो. आणि यामुळेच व्यवसाय-आधारित डेटा आर्किटेक्चर्स इतके महत्त्वपूर्ण आणि आजच्या काळासाठी संबंधित आहेत. आणि मला वाटते, तुम्हाला माहिती आहे, हा केवळ एक गूढ शब्द नाही, तर ही अगदी वास्तविक आहे.
परंतु आपण इतिहासामध्ये डोकावले तर आम्ही त्याबद्दल थोडे अधिक कौतुक करू शकतो, म्हणून वेळेत परत जाऊया, १ s s० च्या दशकात परत जाऊ आणि त्यानंतर काही काळ मेनफ्रेम्सचे वर्चस्व राहिले. त्यानंतर त्यांनी पीसींना मार्ग दाखविला जिथे आपण पीसी आले तेव्हा वापरकर्त्यांची खरोखरच बंडखोरी केली. केंद्रीकृत आयटीविरूद्ध बंडखोरी, ज्यांना त्यांचे मत होते की ते त्यांच्या गरजा पूर्ण करीत नाहीत, ते पुरेसे चपळ नव्हते. जेव्हा पीसी एकत्र जोडले गेले तेव्हा त्याने वितरित संगणनाला पटकन वाढ दिली. आणि मग इंटरनेट होऊ लागले, ज्याने एंटरप्राइझच्या सीमांना अस्पष्ट केले - आता डेटा एक्सचेंजच्या बाबतीत ते स्वतः बाहेरील पक्षांशी संवाद साधू शकतात, जे यापूर्वी झाले नव्हते. आणि आता आम्ही मेघ आणि मोठ्या डेटाच्या युगात गेलो आहोत जिथे क्लाऊड प्लॅटफॉर्म आहे जे खरोखरच पायाभूत सुविधांना कमोडिटीज देत आहेत आणि म्हणून आम्ही सोडत आहोत, जसे की मोठे डेटा सेंटर चालवण्याची गरज आहे कारण आपल्याला माहिती आहे, आमच्याकडे क्लाऊड क्षमता उपलब्ध झाली आहे, आणि एरीककडे असलेल्या त्या मोठ्या डेटासह सुसंगत आहे, आपल्याला माहिती आहे, म्हणूनच इतके स्पष्टपणे चर्चा केली. आणि एकंदरीत, जसे आपण पहात आहोत, तंत्रज्ञानात बदल होताना ते अधिक डेटा-केंद्रित झाले आहे, आम्हाला डेटाबद्दल अधिक काळजी आहे. इंटरनेट प्रमाणेच डेटाची देवाणघेवाण कशी केली जाते. मोठ्या डेटासह, स्वतःच डेटाचे चार किंवा अधिक v.
त्याच वेळी आणि कदाचित सर्वात महत्त्वाचे म्हणजे व्यवसाय वापर प्रकरणे सरकली. जेव्हा संगणक प्रथम सादर केले गेले होते, तेव्हा त्यांची पुस्तके आणि रेकॉर्ड्ससारख्या गोष्टी स्वयंचलित करण्यासाठी वापरली जात होती. आणि मॅन्युअल प्रक्रिया असलेली कोणतीही गोष्ट, ज्यामध्ये लेजर किंवा त्यासारख्या गोष्टींचा समावेश होता, तो प्रोग्राममध्ये, मूलत: घरातच होता. ते 80 च्या दशकात ऑपरेशनल पॅकेजेसच्या उपलब्धतेकडे गेले. आपल्याला यापुढे स्वत: चे वेतनपट लिहिण्याची आवश्यकता नाही, आपण असे काहीतरी विकत घेऊ शकता. याचा परिणाम त्या वेळी बर्याच आयटी विभागात मोठ्या प्रमाणात आकार घसरणे किंवा पुनर्रचना करण्यात आला. परंतु नंतर डेटा वेअरहाऊससारख्या गोष्टींबरोबर व्यवसायातील बुद्धिमत्ता दिसून आले, बहुतेक 90 च्या दशकात. त्यानंतर डॉटकॉम बिझिनेस मॉडेल्स आहेत, जी नक्कीच मोठी उन्माद होती. मग एमडीएम. एमडीएम सह आपण पहात आहात की आम्ही ऑटोमेशनबद्दल विचार करीत नाही; आम्ही फक्त डेटा म्हणून डेटा क्युरेटिंगवर लक्ष केंद्रित करीत आहोत. आणि नंतर विश्लेषणे, आपण डेटामधून मिळवू शकता त्या मूल्याचे प्रतिनिधित्व करतात. आणि विश्लेषकांमध्ये आपण अशा कंपन्या पाहता ज्या बर्याच यशस्वी आहेत ज्याचे मूळ व्यवसाय मॉडेल डेटाभोवती फिरते. गूगल, त्याचाच एक भाग असेल, पण तुम्ही वालमार्ट आहे असा तर्कही करू शकता.
आणि म्हणून व्यवसाय आता डेटाबद्दल खरोखर विचार करत आहे. डेटामधून मूल्य कसे मिळवता येईल? डेटा व्यवसाय, धोरण आणि ड्राइव्ह कशा प्रकारे चालवू शकतो आणि आम्ही डेटाच्या सुवर्ण युगात आहोत. म्हणूनच, आमच्या डेटा आर्किटेक्चरच्या बाबतीत काय घडत आहे, जर डेटा यापुढे अनुप्रयोगांच्या शेवटच्या टप्प्यातून निघणारी एक्झॉस्ट म्हणून गणली जात नाही, परंतु आमच्या व्यवसाय मॉडेलमध्ये खरोखरच ते मध्यवर्ती आहे काय? बरं, आम्हाला प्राप्त होण्यात येणा problem्या समस्येचा एक भाग म्हणजे भूतकाळातील सिस्टम डेव्हलपमेंट लाइफ सायकलमध्ये अडकलेला आहे जो आयटीच्या सुरुवातीच्या वयात त्या प्रक्रियेच्या ऑटोमेशन टप्प्यावर वेगाने सामोरे जाणे आणि त्यात काम करण्याच्या परिणामी होता. प्रकल्प एक समान गोष्ट आहे. आयटीला - आणि हे थोडेसे व्यंगचित्र आहे - परंतु मी काय सांगण्याचा प्रयत्न करीत आहे की व्यवसाय-आधारित डेटा आर्किटेक्चर मिळविण्यातील काही अडथळे कारण आम्ही आयटीमधील एक प्रकारची संस्कृती स्वीकारली आहे. जे पूर्वीच्या वयापासून आले आहे.
तर प्रत्येक गोष्ट प्रकल्प आहे. मला आपल्या आवश्यकता तपशीलवार सांगा. जर गोष्टी कार्यरत नसतील तर आपण मला आपल्या आवश्यकतांबद्दल सांगितले नाही म्हणून असे आहे. हे आज डेटासह कार्य करत नाही कारण आम्ही स्वयंचलित मॅन्युअल प्रक्रियेसह प्रारंभ करीत नाही किंवा आपल्याला माहित आहे की व्यवसाय प्रक्रियेचे तांत्रिक रूपांतरण आहे, आम्ही प्रयत्न करीत असलेल्या विद्यमान उत्पादन डेटासह आम्ही बर्याचदा प्रारंभ करत आहोत. बाहेर मूल्य मिळविण्यासाठी परंतु डेटा-केंद्रित प्रकल्प प्रायोजित करीत असलेल्या कोणालाही खरोखरच हा डेटा सखोलपणे समजत नाही. आम्हाला डेटा डिस्कव्हरी करावी लागेल, आम्हाला सोर्स डेटा विश्लेषण करावे लागेल. आणि हे सिस्टीमच्या विकासाशी खरोखर जुळत नाही, आपल्याला माहिती आहे - धबधबा, एसडीएलसी लाइफसायकल - त्यापैकी चपळ, मी ठेवेल, हे त्या प्रकारचे एक चांगले संस्करण आहे.
आणि ज्यावर लक्ष केंद्रित केले जात आहे ते म्हणजे तंत्रज्ञान आणि कार्यक्षमता, डेटा नाही. उदाहरणार्थ, जेव्हा आम्ही चाचणीच्या टप्प्यात सामान्यत: हे करतो तेव्हा माझी कार्यक्षमता कार्य करते, तर माझ्या ईटीएलला सांगा, पण आम्ही डेटाची तपासणी करीत नाही. आम्ही स्त्रोत डेटा येणार याबद्दल आमच्या गृहितकांची चाचणी करीत नाही. जर आम्ही केले तर आम्ही कदाचित चांगल्या स्थितीत आहोत आणि डेटाबेअर प्रकल्पांचे काम केले आहे आणि माझ्या ईटीएलचा आढावा घेत अपस्ट्रीम बदलांचा सामना केला आहे, अशी मी प्रशंसा करतो. आणि खरं तर, आम्ही काय पाहू इच्छितो ते सतत उत्पादन डेटा गुणवत्ता देखरेखीची प्राथमिक पायरी म्हणून चाचणी घेणे आहे. म्हणून आम्हाला येथे बर्याच दृष्टीकोन प्राप्त झाले आहेत जेथे व्यवसाय-आधारित डेटा आर्किटेक्चर साध्य करणे कठीण आहे कारण प्रक्रिया-केंद्रिततेच्या युगानुसार आम्ही सशक्त आहोत. आम्हाला डेटा-केंद्रिततेत संक्रमण करणे आवश्यक आहे. आणि हे एक संपूर्ण संक्रमण नाही, आपल्याला माहित आहे की तेथे अजून बरेच प्रक्रिया करण्याचे काम आहे, परंतु जेव्हा आपल्याला आवश्यक असेल तेव्हा आम्ही डेटा-केंद्रित दृष्टीने खरोखर विचार करत नाही आणि जेव्हा आपण खरोखर आहोत तेव्हा परिस्थिती ते करण्यास बांधील
आता व्यवसायाला डेटाचे मूल्य समजले, त्यांना डेटा अनलॉक करायचा आहे, मग आम्ही ते कसे करणार आहोत? मग आम्ही संक्रमण कसे करू? बरं, आम्ही विकास प्रक्रियेच्या केंद्रस्थानी डेटा ठेवतो. आणि आम्ही व्यवसायाला माहितीच्या आवश्यकतेसह पुढे जाऊ देतो. आणि आम्हाला समजते की प्रकल्पाच्या सुरूवातीस अस्तित्त्वात असलेला स्रोत डेटा कोणालाही समजत नाही. आपण असा तर्क करू शकता की डेटा स्ट्रक्चर्स आणि डेटा स्वतः अनुक्रमे आयटी आणि ऑपरेशन्सद्वारे तेथे आला आहे, म्हणून आम्हाला हे माहित असले पाहिजे, परंतु खरंच, आम्ही तसे करीत नाही. हा डेटाकेंद्रित विकास आहे. तर डेटा-केंद्रीत जगात आम्ही कुठे आणि आम्ही डेटा मॉडेलिंग कसे करतो या विचाराने, आम्हाला डेटा डिस्कव्हिंग आणि डेटा प्रोफाइलिंग केल्याप्रमाणे वापरकर्त्यांकडे त्यांच्या माहितीच्या आवश्यकता सुधारित करण्याच्या दृष्टीने अभिप्राय लूप असावा लागेल. , स्त्रोत डेटा विश्लेषणाचा अभ्यास करा आणि जसे आम्हाला हळूहळू आमच्या डेटाबद्दल अधिक आणि अधिक निश्चितता मिळेल. आणि आता मी अधिक पारंपारिक प्रकल्प, जसे की एमडीएम हब किंवा डेटा वेअरहाऊस बद्दल बोलतोय, मोठे डेटा प्रकल्प आवश्यक नसतात, जरी हे अजूनही आहे तरीही, मी त्याकडे अगदी जवळ आहे. आणि म्हणून त्या फीडबॅक लूपमध्ये डेटा मॉडेलर्सचा समावेश आहे, आपणास माहित आहे की हळूहळू त्यांच्या डेटा मॉडेलची प्रगती करत आणि स्त्रोताच्या डेटावरून जे शक्य आहे ते, काय उपलब्ध आहे यावर आधारित माहिती आवश्यकते परिष्कृत केल्या आहेत याची खात्री करण्यासाठी वापरकर्त्यांशी संवाद साधत आहेत, म्हणूनच डेटा मॉडेल असण्याची आताची घटना नाही, आपल्याला माहिती आहे, अशा स्थितीत जेथे एकतर तेथे नाही किंवा पूर्ण केले गेले आहे, हे हळूहळू त्याचे लक्ष वेधून घेते.
त्याचप्रमाणे, आमच्याकडे गुणवत्ता आश्वासन आहे जिथे आम्ही डेटा गुणवत्तेच्या चाचणीसाठी नियम विकसित करतो ज्यायोगे डेटा आम्ही ज्या गृहितब्लांवर गृहित धरत आहोत त्या मापदंडाच्या आत डेटा आहे. आत जाताना एरिक संदर्भ डेटामधील बदलांचा संदर्भ देत होता, जे घडू शकते. आपण त्या क्षेत्रामध्ये अप्रबंधित बदलांचा बळी पडलेला, जसे, तो असला पाहिजे, असे होऊ इच्छित नाही, म्हणून गुणवत्ता हमी नियम पोस्ट-प्रॉडक्शन, सतत डेटा गुणवत्ता देखरेखीवर जाऊ शकतात. तर आपण डेटा केंद्रित होणार आहोत की नाही हे पाहणे सुरू करू शकता, डेटा-केंद्रित विकास कसे करतो हे कार्यक्षमता-आधारित एसडीएलसी आणि चपळपणापेक्षा बरेच वेगळे आहे. आणि मग व्यवसायाच्या दृश्यांकडेही लक्ष दिले पाहिजे. आमच्याकडे आहे - आणि पुन्हा हे एरिक काय म्हणत आहे ते प्रतिध्वस्तित करते - आमच्याकडे डेटाबेससाठी डेटा स्टील निळे परिभाषित करणारा एक डेटा मॉडेल आहे, परंतु त्याच वेळी आम्हाला त्या वैचारिक मॉडेल्सची आवश्यकता आहे, डेटाच्या त्या व्यवसाय दृश्यांमध्ये जे पारंपारिकपणे केले गेले नाहीत. भूतकाळ. आम्ही कधीकधी असे केले आहे की मला वाटते की डेटा मॉडेल हे सर्व करू शकते, परंतु आपल्याकडे संकल्पनात्मक दृष्टिकोन, शब्दार्थ आणि डेटा शोधणे आवश्यक आहे, स्टोअर मॉडेलचे व्यवसायात रुपांतर करणार्या अॅब्स्ट्रॅक्शन लेयरद्वारे प्रस्तुत करणे आवश्यक आहे. पहा. आणि पुन्हा, एरिक शब्दांविषयी ज्या गोष्टींबद्दल बोलत होते, ते करणे महत्वाचे होते, म्हणून आपल्याकडे मॉडेलिंगची अतिरिक्त कार्ये आहेत. मला वाटते की हेच आहे, आपल्याला माहिती आहे, आपण जसे मी केले तसेच डेटा मॉडेलर म्हणून रॅंकमध्ये आला तर पुन्हा काहीतरी नवीन.
आणि शेवटी मी म्हणायचे आहे की मोठ्या आर्किटेक्चरमध्ये देखील हे नवीन वास्तव प्रतिबिंबित झाले आहे. उदाहरणार्थ पारंपारिक ग्राहक एमडीएम हा एक प्रकारचा आहे, ठीक आहे, आपला ग्राहक डेटा एका हबमध्ये येऊ या, जेथे आपल्याला माहित आहे, बॅक ऑफिस अनुप्रयोगांसाठी फक्त डेटा गुणवत्तेच्या दृष्टीने त्याचा अर्थ काढू शकतो. व्यवसाय धोरणाच्या दृष्टीकोनातून हा एक होकाराचा प्रकार आहे. तथापि, आज आम्ही ग्राहकांच्या एमडीएम हबकडे पहात आहोत ज्यात अतिरिक्त ग्राहक प्रोफाइल डेटा आहे, केवळ स्थिर डेटाच नाही, ज्यामध्ये खरोखर ग्राहकांच्या व्यवहाराच्या अनुप्रयोगांसह द्विदिशात्मक संवाद आहे. होय, ते अद्याप मागील कार्यालयात समर्थन देतात, परंतु आता आम्हाला आमच्या ग्राहकांच्या या वर्तनाबद्दल देखील माहिती आहे. हे बांधणे अधिक महाग आहे. हे तयार करणे अधिक जटिल आहे. परंतु पारंपारिक ग्राहक एमडीएम नसलेल्या मार्गाने हे व्यवसाय-चालित आहे. आपण अंमलात आणणे सोपे आहे अशा सोप्या डिझाईन्सच्या विरूद्ध व्यवसायाकडे जाण्याकडे दुर्लक्ष करीत आहात, परंतु व्यवसायासाठी त्यांना हे पहायचे आहे. आम्ही खरोखरच एका नवीन युगात आहोत आणि मला असे वाटते की व्यवसाय-ड्रायव्हिंग डेटा आर्किटेक्चरला प्रतिसाद मिळावा अशी बर्याच पातळी आहेत आणि मला वाटते की गोष्टी करण्याचा हा खूप आनंददायक समय आहे.
तर रिबेका, परत धन्यवाद.
रेबेका जोझवियाक: धन्यवाद माल्कम, आणि डेटा मॉडेल बद्दल तुम्ही जे बोललात त्याचा आनंद मला नक्कीच घ्यावा जेणेकरून व्यवसायाचे दृश्य नक्कीच खायला हवे, कारण तुम्ही जे काही बोलता त्यापेक्षा वेगळ्या प्रकारे, जिथे आयटीने इतके दिवस कडक शासन केले आणि आता त्या प्रकारची नाही आणि ती संस्कृती शिफ्ट करण्याची आवश्यकता नाही. आणि मला खात्री आहे की पार्श्वभूमीत एक कुत्रा होता जो आपल्याशी 100% सहमत होता. आणि त्यासह मी चेंडू रॉनकडे जात आहे. मी आपला डेमो पाहून खरोखर उत्साही आहे रॉन, मजला आपला आहे
रॉन हुईझेन्गा: मनापासून धन्यवाद आणि आम्ही त्यात जाण्यापूर्वी, मी काही स्लाइड्समधून आणि नंतर थोडासा डेमो घेईन कारण, एरिक आणि माल्कम यांनी सांगितल्याप्रमाणे, हा एक अतिशय विस्तृत आणि सखोल विषय आहे आणि आम्ही ज्याद्वारे आज आपण याबद्दल बोलत आहोत की आपण फक्त त्या पृष्ठभागावर स्क्रॅप करत आहोत कारण बर्याच पैलू आणि बर्याच गोष्टी आहेत ज्याचा आपल्याला व्यवसाय-आधारित आर्किटेक्चरकडून विचार करणे आवश्यक आहे. आमचा दृष्टीकोन त्या मॉडेलवर आधारित खरोखर बनविणे आणि मॉडेल्समधून वास्तविक मूल्य मिळविणे हा आहे कारण आपण त्यांचा उपयोग संप्रेषण वाहन म्हणून तसेच इतर प्रणाली सक्षम करण्यासाठी एक थर म्हणून करू शकता. आपण सेवा-देणारं आर्किटेक्चर करत असाल किंवा इतर गोष्टी, मॉडेल जे काही चालू आहे त्याचा त्या आजूबाजूचा सर्व मेटाडेटा आणि आपल्या व्यवसायातील डेटासह खरोखरच त्याचा जीवनवाह बनतो.
मला जे बोलायचे आहे, ते जवळजवळ हे एक पाऊल मागे टाकत आहे, कारण समाधान कसे विकसित झाले आहे आणि त्या प्रकारच्या प्रकाराच्या इतिहासावर माल्कमने स्पर्श केला होता. साउंड डेटा आर्किटेक्चर असणे खरोखर महत्वाचे आहे हे दाखवण्याचा एक मार्ग म्हणजे उत्पादन व्यवस्थापनाच्या भूमिकेत येण्यापूर्वी मी सल्लामसलत करता तेव्हा मी बर्याचदा वापरात जायचा आणि तो होता, मी संस्थांमध्ये जात असे ते व्यवसायात बदल घडवून आणत असत किंवा काही अस्तित्त्वात असलेल्या प्रणाली आणि त्या प्रकारच्या वस्तू पुनर्स्थित करीत असत किंवा असमाधानकारक संस्था त्यांचा स्वतःचा डेटा कसा समजतात हे अगदी लवकर दिसून आले. आपण यासारख्या विशिष्ट वापराचे प्रकरण घेतल्यास, आपण सल्लागार असलात किंवा कदाचित ही अशी व्यक्ती आहे जी नुकतीच एखाद्या संस्थेने सुरू केली असेल किंवा आपली संस्था बर्याच वर्षांत वेगवेगळ्या कंपन्या ताब्यात घेऊन तयार झाली आहे, आपण काय समाप्त केले आहे अप हे एक अतिशय गुंतागुंतीचे वातावरण आहे, ज्यात बरेच नवीन तंत्रज्ञान, तसेच लीगेसी तंत्रज्ञान, ईआरपी समाधानासह इतर सर्व गोष्टी आहेत.
म्हणून आपल्या मॉडेलिंगच्या दृष्टिकोनासह आपण खरोखर करू शकू अशा गोष्टींपैकी एक म्हणजे या सर्व गोष्टींचा मी अर्थ कसा काढू शकतो या प्रश्नाचे उत्तर देणे. आम्ही खरोखरच एकत्रितपणे माहिती एकत्रित करण्यास प्रारंभ करू शकतो, जेणेकरून व्यवसायाने आमच्याकडे योग्य प्रकारे माहिती मिळवू शकेल. आणि हे समोर येते, त्या वातावरणात आपल्याकडे असे काय आहे? मला आवश्यक असलेली माहिती काढण्यासाठी मी ती मॉडेल कशी वापरू शकेन आणि ती माहिती अधिक चांगल्या प्रकारे समजून घेऊ? आणि नंतर आमच्याकडे रिलेशनल डेटा मॉडेलसारख्या सर्व भिन्न गोष्टींसाठी मेटाडेटाचे पारंपारिक प्रकार आहेत आणि परिभाषा आणि डेटा शब्दकोष, आपल्याला माहिती आहे अशा डेटा प्रकार आणि त्या प्रकारची वस्तू पाहण्याची आमची आवड आहे. परंतु त्यास खरोखर आणखी अर्थपूर्ण बनविण्यासाठी आपण कॅप्चर करू इच्छित अतिरिक्त मेटाडेटाचे काय? जसे की, खरोखर कोणत्या घटकांना संदर्भ डेटा ऑब्जेक्ट्स असावेत, जे मास्टर डेटा मॅनेजमेन्ट ऑब्जेक्ट्स आणि त्या प्रकारच्या गोष्टी असाव्यात आणि त्यांना एकत्र बांधून ठेवले पाहिजेत. आणि संस्थेद्वारे माहिती कशी दिली जाते? प्रक्रियेच्या दृष्टीकोनातून त्यांचा कसा वापर केला जातो त्यावरून डेटा वाहतो, परंतु आमच्या व्यवसायांद्वारे माहितीच्या प्रवासाच्या दृष्टीने डेटा वंश आणि विविध सिस्टमद्वारे किंवा डेटा स्टोअरद्वारे कसा मार्गक्रमण करतो याबद्दल आम्हाला माहिती आहे. जेव्हा आम्ही आय-सोल्यूशन्स किंवा त्या प्रकारच्या गोष्टी तयार करीत असतो, तेव्हा आम्ही हातांनी केलेल्या कामासाठी वास्तविक माहिती वापरत असतो.
आणि मग सर्वात महत्त्वाचे म्हणजे आम्ही त्या सर्व भागधारकांना आणि विशेषत: व्यवसायातील भागीदारांना एकत्र कसे आणू शकतो कारण तेच त्या डेटामुळे काय आहेत याचा खरा अर्थ देतात. दिवसाच्या शेवटी, व्यवसायाकडे डेटा असतो. ते एरिक बोलत असलेल्या शब्दसंग्रह आणि गोष्टींसाठी व्याख्या प्रदान करतात, म्हणून आम्हाला त्या सर्वांना एकत्र बांधण्यासाठी जागेची आवश्यकता आहे. आमचा डेटा मॉडेलिंग आणि डेटा रिपॉझिटरी आर्किटेक्चर्सद्वारे आम्ही ते करतो.
मी काही गोष्टींवर स्पर्श करणार आहे. मी ईआर / स्टुडिओ एंटरप्राइझ टीम संस्करण बद्दल बोलत आहे. मुख्यतः मी डेटा आर्किटेक्चर उत्पादनाबद्दल बोलत आहे जिथे आम्ही डेटा मॉडेलिंग करतो आणि त्या प्रकारच्या गोष्टी, परंतु त्या स्वीटचे बरेच घटक आहेत ज्यांचा मी फक्त थोडक्यात स्पर्श करेन. आपल्याला व्यवसाय आर्किटेक्टचा एक झलका दिसतो, जिथे आम्ही वैचारिक मॉडेल्स करू शकतो, परंतु आम्ही व्यवसाय प्रक्रिया मॉडेल देखील करू शकतो आणि आमच्या डेटा मॉडेलमध्ये असलेल्या वास्तविक डेटाचा दुवा साधण्यासाठी आम्ही त्या प्रक्रिया मॉडेलना बांधू शकतो. हे टाय एकत्र आणण्यास खरोखर मदत करते. सॉफ्टवेअर आर्किटेक्ट आम्हाला अशी काही बांधकामं करण्यास अनुमती देते जसे की काही यूएमएल मॉडेलिंग आणि अशा प्रकारच्या गोष्टी ज्या आम्ही बोलत आहोत त्यापैकी काही सिस्टीम आणि प्रक्रियांना सहाय्यक लॉजिक्स देतात. परंतु सर्वात महत्त्वाचे म्हणजे आम्ही खाली जात असताना आमच्याकडे रेपॉजिटरी आणि कार्यसंघ सर्व्हर आहे आणि मी त्याबद्दल एकाच गोष्टीचे दोन भाग म्हणून बोलतो. रेपॉजिटरी असे आहे जेथे आम्ही सर्व मॉडेलिंग मेटाडेटा तसेच सर्व व्यवसाय मेटाडेटा व्यवसायाच्या शब्दावली आणि अटींच्या संचयनात ठेवतो. आणि आमच्याकडे हे रेपॉजिटरी-आधारित वातावरण असल्यामुळे आपण नंतर या सर्व भिन्न गोष्टी एकाच वातावरणात एकत्र जोडू शकतो आणि मग त्या वस्तू केवळ तांत्रिक लोकांसाठीच नव्हे तर व्यावसायिकांसाठी देखील उपलब्ध करुन देऊ शकतो. आणि अशाप्रकारे आम्ही खरोखर सहकार्य करणे सुरू करतो.
आणि मग मी थोडक्यात सांगत असलेला शेवटचा तुकडा म्हणजे जेव्हा आपण या वातावरणात जाता तेव्हा हे फक्त तेथे डेटाबेस असतात असे नाही. आपल्याकडे पुष्कळ डेटाबेस, डेटा स्टोअर्स असणार आहेत, आपल्याकडे बरेच काही देखील आहेत, मी काय म्हणतो, वारसा कृत्रिमता. कदाचित लोकांनी काही गोष्टी तयार करण्यासाठी व्हिजिओ किंवा इतर आकृत्या वापरल्या असतील. कदाचित त्यांच्याकडे मॉडेलिंगची इतर साधने आणि त्या प्रकारची वस्तू असतील.तर आपण मेटावॉयार्ड सह जे काही करू शकतो ते म्हणजे त्यातील काही माहिती काढणे आणि ती आपल्या मॉडेल्समध्ये आणणे, त्यास वर्तमान बनवा आणि ते वापरण्यात सक्षम व्हा, त्यास सध्या बसून न बसण्याऐवजी पुन्हा वापर करा. हे आता आमच्या कार्यरत मॉडेलचा सक्रिय भाग बनले आहे, जे फार महत्वाचे आहे.
जेव्हा आपण एखाद्या संघटनेत प्रवेश करता, जसे मी म्हणालो, तेथे बर्याच वेगळ्या यंत्रणा बाहेर असतात, भरपूर ईआरपी सोल्यूशन्स, न जुळणारे विभागीय निराकरण. बर्याच संस्था सास सोल्यूशन्स देखील वापरत आहेत, जी बाह्यरित्या नियंत्रित आणि व्यवस्थापित देखील आहेत, म्हणून आम्ही त्यावरील होस्टमध्ये डेटाबेस आणि त्या प्रकारच्या गोष्टींवर नियंत्रण ठेवत नाही, परंतु आपल्याला अद्याप डेटा कसा दिसतो हे माहित असणे आवश्यक आहे आणि अर्थातच, त्याभोवती मेटाडेटा. आम्हाला देखील सापडत आहे की बर्याच अप्रचलित परंपरागत प्रणाली आहेत जी मॅल्कमने ज्या प्रकल्प-आधारित पध्दतीविषयी बोलल्या आहेत त्यामुळे साफ केल्या गेल्या नाहीत. अलिकडच्या वर्षांत संस्था प्रकल्प कसे फिरवतील हे आश्चर्यकारक आहे, ते सिस्टम किंवा सोल्यूशनची जागा घेतील, परंतु बहुतेक वेळेस अप्रचलित निराकरणास प्रकल्प रद्द करण्यास पुरेसे बजेट शिल्लक राहत नाही, म्हणून आता ते फक्त मार्गात आहेत. आणि आपल्या वातावरणात आपण खरोखर काय मुक्त होऊ शकतो तसेच पुढे काय उपयुक्त आहे हे शोधून काढले पाहिजे. आणि ते खराब निर्णयाची पध्दतशी संबंधित आहे. तो त्याच गोष्टीचा भाग आणि पार्सल आहे.
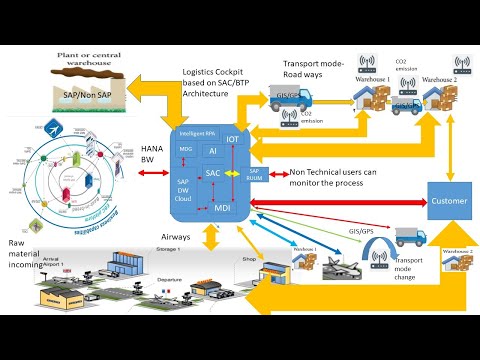
आम्हाला काय सापडते, कारण या सर्व भिन्न निराकरणावरून बर्याच संस्था तयार केल्या गेल्या आहेत, तर बर्याच ठिकाणी बरेच डेटा फिरत असताना आपल्याला बर्याच पॉईंट-टू-पॉईंट इंटरफेस दिसत आहेत. आम्हाला ते तर्कसंगत करण्यास सक्षम असणे आवश्यक आहे आणि मी आकडेवारीने आधी उल्लेख केलेला डेटा वंशाचा आकडा शोधून काढणे आवश्यक आहे जेणेकरून आपल्याकडे सेवा-देणार्या आर्किटेक्चरचा उपयोग, एंटरप्राइझ सर्व्हिस बस आणि त्या प्रकारच्या गोष्टींसारखी अधिक सुसंगत रणनिती असू शकेल, योग्य माहिती देण्यासाठी आम्ही आमच्या व्यवसायात योग्यरित्या वापरत असलेल्या मॉडेलच्या प्रकाशित आणि सदस्यता प्रकारावर आहोत. आणि मग अर्थातच, आम्ही काही प्रकारचे areनालिटिक्स करणे आवश्यक आहे, आम्ही डेटा वेअरहाउस वापरत असलो किंवा नाही, पारंपारिक ईटीएलसह डेटा मार्ट वापरत आहोत किंवा काही नवीन डेटा तलाव वापरत आहोत. हे सर्व एकाच गोष्टीवर खाली येते. हा सर्व डेटा आहे, हा मोठा डेटा आहे की नाही, रिलेशनल डेटाबेसमधील पारंपारिक डेटा आहे की नाही, आम्हाला तो सर्व डेटा एकत्र आणण्याची आवश्यकता आहे जेणेकरुन आम्ही ते व्यवस्थापित करू आणि आमच्या मॉडेल्समध्ये आम्ही काय वागतो हे जाणून घेऊ.
पुन्हा, आम्ही ज्या जटिलतेमध्ये कार्य करणार आहोत ती म्हणजे आपल्याकडे असंख्य चरण आहेत जे आपण करू इच्छित आहोत. सर्व प्रथम, आपण चालत आहात आणि त्या माहिती लँडस्केप कशा दिसत आहे याचा आपल्याकडे ब्लू असू शकत नाही. ईआर / स्टुडिओ डेटा आर्किटेक्ट सारख्या डेटा मॉडेलिंग टूलमध्ये आपण प्रथम तेथे असलेल्या डेटा स्रोतांकडे लक्ष देऊ या की त्या संदर्भात बरेच उलट अभियांत्रिकी करत आहात, त्यांना आणा आणि नंतर त्यांना अधिक प्रतिनिधींमध्ये एकत्र टाका. संपूर्ण व्यवसायाचे प्रतिनिधित्व करणारे मॉडेल. महत्त्वाची गोष्ट म्हणजे, आम्हाला ती मॉडेल तसेच व्यवसायाच्या धर्तीवर विघटन करण्यास सक्षम व्हायचे आहे जेणेकरुन आम्ही त्यांच्याशी संबंधित होऊ शकू लहान छोट्या भागांमध्ये, ज्याचे आमचे व्यवसायिक लोक देखील संबंधित असू शकतात आणि आमचे व्यवसाय विश्लेषक आणि इतर भागधारक जे कार्यरत आहेत. त्यावर.
नावे ठेवणे निकष अत्यंत महत्वाचे आहेत आणि मी याबद्दल येथे काही वेगवेगळ्या मार्गांनी बोलत आहे. आम्ही आमच्या मॉडेल्समधील गोष्टी कशा नामित करतो या संदर्भात नाव ठेवण्याचे मानक. तार्किक मॉडेल्समध्ये हे करणे हे अगदी सोपे आहे, जिथे आपल्याकडे आमच्या मॉडेलसाठी एक चांगले नामकरण संमेलन आणि एक चांगला डेटा शब्दकोश आहे, परंतु नंतर देखील, आम्ही आणत असलेल्या या भौतिक मॉडेलच्या बर्याच नावांसाठी वेगवेगळ्या नावे संमेलने पाहतो. जेव्हा आम्ही रिव्हर्स इंजिनियर, बर्याचदा आम्ही संक्षेपित नावे आणि त्या प्रकारची गोष्ट पाहतो. आणि त्या परत व्यवसायात अर्थपूर्ण असलेल्या इंग्रजी नावांमध्ये त्या भाषांतरित करणे आवश्यक आहे जेणेकरून वातावरणात आपल्याकडे असलेले हे सर्व डेटा तुकडे काय आहे हे आम्हाला समजू शकेल. आणि मग सार्वत्रिक मॅपिंग्ज असे आहे की आम्ही त्यांना एकत्र कसे जोडतो.
त्या शीर्षस्थानी आम्ही नंतर दस्तऐवजीकरण आणि परिभाषित करू आणि तिथेच आम्ही अॅटॅचमेंट्स नावाच्या वस्तूसह आपला डेटा वर्गीकृत करू शकतो, त्यावरील काही स्लाइड मी तुम्हाला दाखवतो. आणि मग पळवाट बंद केल्यावर आपण त्या व्यवसायाचा अर्थ लागू करू इच्छित आहोत, जिथे आपण आपल्या व्यवसायातील शब्दावली बनवतो आणि त्या आपल्या भिन्न मॉडेल कलाकृतींशी जोडू शकतो, म्हणून जेव्हा आपण एखाद्या विशिष्ट व्यवसायाच्या संज्ञेबद्दल बोलत असतो, तेव्हा ते आपल्याला माहित असते. आमच्या संस्थेमध्ये संपूर्ण डेटा लागू केला. आणि शेवटी मी आधीच या गोष्टीबद्दल बोललो आहे की बर्याच सहयोग आणि प्रकाशनाच्या क्षमतेवर आधारित हे सर्व आम्हाला भांडार असणे आवश्यक आहे, जेणेकरून आमचे हितधारक त्याचा उपयोग करु शकतील. मी रिव्हर्स इंजिनीअरिंगबद्दल बर्याच लवकर बोलणार आहे. मी यापूर्वीच एक प्रकारचा वेगवान हायलाइट दिला आहे. आम्ही तिथे आणू शकू अशा काही गोष्टी तुम्हाला दाखवण्यासाठी मी प्रत्यक्ष डेमोमध्ये हे दर्शवीन.
आणि मला असे काही मॉडेल प्रकार आणि आकृत्यांबद्दल सांगायचे आहे जे आपण या प्रकारच्या परिस्थितीमध्ये तयार करू. अर्थात आम्ही बर्याच घटनांमध्ये वैचारिक मॉडेल्स करू; मी यावर जास्त वेळ घालवणार नाही. मला खरोखरच लॉजिकल मॉडेल्स, फिजिकल मॉडेल्स आणि आम्ही तयार करू शकणार्या खास प्रकारच्या मॉडेल्सविषयी बोलू इच्छितो. आणि हे महत्त्वाचे आहे की आम्ही हे सर्व एकाच मॉडेलिंग प्लॅटफॉर्ममध्ये तयार करु जेणेकरुन आम्ही त्यांना एकत्र टाका. त्यात मितीय मॉडेल आणि मी दाखवलेल्या NoSQL सारख्या काही नवीन डेटा स्रोतांचा वापर करणारे मॉडेल्स देखील आहेत. आणि मग, डेटा वंशाचे मॉडेल कसे दिसते? आणि आम्ही त्या डेटा व्यवसायाच्या प्रक्रियेच्या मॉडेलमध्ये कसा टाकायचा, आपण पुढील गोष्टींबद्दल बोलत आहोत.
मी आपल्याला फक्त अगदी उच्च आणि द्रुत विहंगावलोकन देण्यासाठी येथे मॉडेलिंग वातावरणाकडे स्विच करणार आहे. आणि माझा विश्वास आहे की आपण आता माझी स्क्रीन पाहण्यास सक्षम असावे. सर्व प्रथम मी फक्त पारंपारिक प्रकारच्या डेटा मॉडेलबद्दल बोलू इच्छितो. आम्ही जेव्हा मॉडेलमध्ये आणतो तेव्हा आम्हाला ज्या पद्धतीने संयोजित करायचे असते, त्याप्रमाणे आपण त्यांचे विघटन करण्यास सक्षम होऊ इच्छित आहोत. तर आपण येथे डाव्या बाजूस काय पहात आहात आमच्याकडे या विशिष्ट मॉडेल फाइलमध्ये तार्किक आणि भौतिक मॉडेल आहेत. पुढील गोष्ट अशी आहे की आम्ही व्यवसायातील विघटनांसह तोडू शकतो, म्हणूनच आपण फोल्डर्स पाहता. फिकट निळे रंगाचे तार्किक मॉडेल आहेत आणि हिरव्या रंगाचे भौतिक मॉडेल आहेत. आणि आम्ही ड्रिल देखील करू शकतो, म्हणून ईआर / स्टुडिओमध्ये, जर आपल्याकडे व्यवसायाची विघटन होत असेल तर आपण आपल्या पातळीवर अनेक स्तर खोल किंवा उप-मॉडेल जाऊ शकता आणि आपण खालच्या स्तरावर केलेले बदल आपोआप उच्च पातळीवर प्रतिबिंबित होऊ शकतात पातळी. म्हणूनच हे खूप द्रुत मॉडेलिंग वातावरण बनते.
ही माहिती एकत्र आणण्यास प्रारंभ करणे खूप महत्वाचे आहे हे मी देखील सांगू इच्छितो की आपल्याकडे एकाधिक भौतिक मॉडेल असू शकतात जे एका लॉजिकल मॉडेलशी सुसंगत असतात. बर्याचदा आपल्याकडे लॉजिकल मॉडेल असू शकते परंतु आपल्याकडे वेगवेगळ्या प्लॅटफॉर्मवर आणि त्या प्रकारात भौतिक मॉडेल्स असू शकतात. कदाचित एखाद्याचे एसक्यूएल सर्व्हरचे उदाहरण असू शकेल, कदाचित दुसर्याचे ओरॅकल उदाहरण असेल. आपल्या सर्वांमध्ये समान मॉडेलिंग वातावरणात एकत्र बांधण्याची क्षमता आहे. आणि तेथे पुन्हा, जे मला येथे मिळाले ते एक वास्तविक डेटा वेअरहाउस मॉडेल आहे जे पुन्हा त्याच मॉडेलिंग वातावरणात असू शकते किंवा आमच्याकडे ते भांडारात असू शकते आणि त्यास वेगवेगळ्या गोष्टींमध्ये देखील जोडले जाऊ शकते.
मला यात खरोखर जे दाखवायचे होते ते म्हणजे आपण ज्या मॉडेलमध्ये प्रवेश करतो त्यापैकी काही इतर गोष्टी आणि इतर प्रकार आहेत. म्हणून जेव्हा आम्ही यासारख्या पारंपारिक डेटा मॉडेलमध्ये प्रवेश करतो तेव्हा आपण कॉलम आणि मेटाडेटा आणि त्या प्रकारच्या वस्तू असलेल्या विशिष्ट घटकांना पाहण्याची सवय लावू शकतो, परंतु जेव्हा आम्ही या काही नवीन एसएसक्यूएल तंत्रज्ञानाचा सामना करण्यास प्रारंभ करतो तेव्हा ते दृष्य बदलते. किंवा काही लोक अद्याप त्यांना कॉल करू इच्छितात म्हणून मोठी डेटा तंत्रज्ञान.
तर आता असे समजूया की आम्हाला आपल्या वातावरणात पोळे देखील मिळाले आहेत. जर आपण एका एचआयव्ही वातावरणापासून अभियंता रिव्हर्स केले तर - आणि आम्ही याच अचूक मॉडेलिंग साधनासह एचआयव्हीकडून अभियंता अग्रेषित करू शकतो आणि त्यास उलट करू शकतो - आपल्याला काहीतरी वेगळे दिसले आहे. आम्ही अजूनही तेथे बांधकामे म्हणून सर्व डेटा पाहतो, परंतु आमचा टीडीएल वेगळा आहे. तुमच्यापैकी जे एसक्यूएल पाहण्याची सवय आहेत, आपण आता काय पहाल ते हाइव्ह क्यूएल आहे, जे अगदी एसक्यूएलसारखे आहे परंतु त्याच साधनामुळे आपण आता विविध स्क्रिप्टिंग भाषांमध्ये कार्य करण्यास सक्षम आहात. म्हणून आपण या वातावरणात मॉडेल बनवू शकता, त्यास पोळ्याच्या वातावरणात तयार करू शकता, परंतु त्याहूनही महत्त्वाचे म्हणजे मी ज्या परिस्थितीत वर्णन केले आहे त्या परिस्थितीत आपण या सर्व अभियंत्यास उलट करू शकता आणि त्यास अर्थ प्राप्त करू शकता आणि त्यास एकत्र जोडणे देखील प्रारंभ करू शकता. .
चला जरा वेगळं असलं तरी अजून एक घेऊ. मुंगोडीबी हे आणखी एक व्यासपीठ आहे ज्याला आम्ही जन्मजात समर्थन करतो. आणि जेव्हा आपण JSON प्रकारच्या वातावरणामध्ये प्रवेश करणे प्रारंभ करता जिथे आपल्याकडे दस्तऐवज स्टोअर आहेत, JSON चे एक भिन्न प्राणी आहे आणि त्यामध्ये काही रचना आहेत, जे रिलेशनल मॉडेलशी संबंधित नाहीत. जेव्हा आपण जेएसओएनची चौकशी करण्यास प्रारंभ करता तेव्हा एम्बेडेड ऑब्जेक्ट्स आणि ऑब्जेक्ट्सच्या एम्बेड अॅरे यासारख्या संकल्पनांवर आपण लवकरच व्यवहार करण्यास प्रारंभ करता आणि पारंपारिक संबंधात्मक नोटेशनमध्ये त्या संकल्पना अस्तित्त्वात नाहीत. आम्ही येथे काय केले तेच आम्ही त्याच वातावरणात हाताळण्यास सक्षम होण्यासाठी नोटेशन आणि आमच्या कॅटलॉगला वास्तविकपणे विस्तारित केले आहे.
आपण इकडे डाव्या बाजूला पाहिले तर घटक आणि सारण्या यासारख्या गोष्टी पाहण्याऐवजी आम्ही त्यांना वस्तू म्हणत आहोत. आणि आपल्याला भिन्न नोटेशन दिसतील. आपण अद्याप येथे संदर्भित सूचनांचे वैशिष्ट्यपूर्ण प्रकार पाहता, परंतु या विशिष्ट आकृतीमध्ये मी दाखवित असलेल्या या निळ्या संस्था खरोखरच अंतःस्थापित वस्तू आहेत. आणि आम्ही भिन्न कार्डिनॅलिटीज दर्शवितो. डायमंड कार्डिनॅलिटी म्हणजे ते एका टोकावरील ऑब्जेक्ट आहे, परंतु एकाच्या कार्डिनॅलिटीचा अर्थ असा आहे की आपल्याकडे प्रकाशकांमध्ये जर आपण त्या नातीचे अनुसरण केले तर आपल्याकडे एम्बेड केलेला पत्ता ऑब्जेक्ट आहे. जेएसओएनची चौकशी करताना आम्हाला आढळले की ही संरक्षकामध्ये एम्बेड केलेल्या वस्तूंची अगदी तशीच रचना आहे परंतु ती प्रत्यक्षात वस्तूंच्या अॅरे म्हणून अंतःस्थापित आहे. आम्ही हे पहात आहोत, केवळ स्वत: कनेक्टरद्वारेच नव्हे तर आपण वास्तविक संस्थांकडे पाहिले तर आपल्याला दिसेल की संरक्षक अंतर्गत पत्ते आपल्याला त्या वस्तूंच्या अॅरे म्हणून वर्गीकृत देखील करतात. आपण ते कसे आणू शकता याबद्दल आपल्याला एक वर्णनात्मक दृष्टीकोन मिळेल.
आणि पुन्हा, आतापर्यंत आम्ही काही सेकंदात जे काही पाहिले आहे ते पारंपारिक रिलेशनल मॉडेल आहेत जे बहु-स्तरीय आहेत, आम्ही पोळ्याबरोबरही तेच करू शकतो, तसेच आम्ही मोंगोडीबी आणि इतर मोठ्या डेटा स्रोतांसह तेच करू शकतो. चांगले. आम्ही काय करू शकतो आणि मी हे आपल्याला लवकरच दर्शवित आहे, मी इतर वेगवेगळ्या क्षेत्रातून गोष्टी आणण्याच्या गोष्टीबद्दल बोललो. मी गृहित धरणार आहे की मी डेटाबेस वरून एक मॉडेल आयात करणार आहे किंवा हे रिव्हर्स इंजिनियर आहे, परंतु मी बाह्य मेटाडेटामधून ते आणणार आहे. आम्ही आणू शकू अशा सर्व प्रकारच्या भिन्न प्रकारच्या गोष्टींबद्दल आपल्याला अगदी द्रुत दृष्टीकोन देण्यासाठी.
आपण पहातच आहात की आपल्याकडे असंख्य गोष्टी आहेत ज्यासह आम्ही आमच्या मॉडेलिंग वातावरणात मेटाडेटा प्रत्यक्षात आणू शकतो. अगदी अॅमेझॉन रेडशिफ्ट, कॅसँड्रा, इतर बरेच मोठे डेटा प्लॅटफॉर्म सारख्या गोष्टींपासून प्रारंभ करीत आहे, जेणेकरून आपल्याला यापैकी बरेच सूचीबद्ध दिसेल. हे वर्णक्रमानुसार आहे. आम्ही बरेच मोठे डेटा स्रोत आणि त्या प्रकारची वस्तू पहात आहोत. आम्ही बरेच पारंपारिक किंवा जुने मॉडेलिंग वातावरण देखील पहात आहोत जे आम्ही प्रत्यक्षात तो मेटाडेटा आणू शकतो. जर मी इथून गेलो - आणि मी त्या प्रत्येकावर वेळ घालवणार नाही - मॉडेलिंग प्लॅटफॉर्म आणि डेटा प्लॅटफॉर्मच्या दृष्टीने आम्ही त्यातून बर्याच गोष्टी आणू शकतो. आणि ज्या गोष्टी येथे लक्षात ठेवणे फार महत्वाचे आहे त्याचा दुसरा भाग म्हणजे आम्ही डेटा वंशाबद्दल बोलणे सुरू केल्यावर एंटरप्राइज टीम एडिशनवर आम्ही ईटीएल स्त्रोतांची चौकशी देखील करू शकतो, ते कॅलेंडर किंवा एसक्यूएल सर्व्हर इन्फॉर्मेशन सर्व्हिसेस मॅपिंगसारख्या गोष्टी असू शकतात. प्रत्यक्षात आमचे डेटा वंश आकृती देखील सुरू करण्यासाठी आणा आणि त्या परिवर्तनांमध्ये काय घडते हे चित्र काढा. बॉक्सच्या बाहेर आमच्याकडे 130 हून अधिक पुल आहेत जे खरंच एंटरप्राइज टीम संस्करण उत्पादनाचे भाग आहेत, जेणेकरून आम्हाला खरोखरच सर्व कलाकृती एका मॉडेलिंग वातावरणात त्वरेने एकत्रितपणे आणण्यास मदत करते.
सर्वात कमी पण नाही, मी डेटा वेअरहाउसिंग किंवा कोणत्याही प्रकारचे ticsनालिटिक्स करत असल्यास आम्हाला इतर प्रकारच्या बांधकामांची आवश्यकता आहे ही वस्तुस्थिती आपण गमावू शकत नाही या वस्तुस्थितीबद्दल देखील बोलू इच्छितो. आमच्याकडे अद्याप आमच्याकडे फॅक्ट टेबल आहेत आणि आमच्याकडे आयाम आणि अशा प्रकारच्या गोष्टी आहेत अशा आयामी मॉडेलसारख्या गोष्टी करण्याची क्षमता आमच्यात आहे. मला एक गोष्ट देखील दाखवायची आहे ती म्हणजे आमच्या मेटाडेटामध्ये विस्तार देखील असू शकतात ज्यामुळे परिमाणांचे प्रकार आणि इतर सर्व गोष्टींचे वर्गीकरण करण्यात मदत होते. म्हणून मी जर येथे आयामी डेटा टॅब पाहिला, उदाहरणार्थ, यापैकी एकावर, तो पाहतो त्या मॉडेलच्या नमुन्यावर आधारित, आपोआप स्वयंचलितपणे ते शोधून काढेल आणि आपल्याला त्यास आयाम आहे किंवा नाही हे समजते की प्रारंभिक बिंदू देईल तथ्य सारणी. परंतु त्याही पलीकडे, आम्ही जे करू शकतो ते परिमाणांमधील आहे आणि त्या प्रकारच्या गोष्टींमध्ये आमच्याकडे भिन्न प्रकारचे परिमाण देखील आहेत जे आम्ही डेटा वेअरहाउसिंगच्या वातावरणामध्ये डेटा वर्गीकृत करण्यासाठी वापरू शकतो. खूप शक्तिशाली क्षमता जे आम्ही यासह पूर्णपणे जोडत आहोत.
मी आत्ता डेमो वातावरणात असल्याने मी यात उडी मारणार आहे आणि स्लाइड्सवर परत जाण्यापूर्वी तुम्हाला इतर काही गोष्टी दाखवणार आहे. आम्ही नुकतेच ईआर / स्टुडिओ डेटा आर्किटेक्टमध्ये जोडलेल्या गोष्टींपैकी एक म्हणजे आम्ही परिस्थितीत धावलो आहोत - आणि जेव्हा आपण प्रकल्पांवर काम करत असता तेव्हा वापरात असलेली ही एक सामान्य गोष्ट आहे - विकसक वस्तूंच्या बाबतीत विचार करतात, तर आमचा डेटा मॉडेलर्स टेबल आणि घटक आणि त्या प्रकारच्या गोष्टींच्या बाबतीत विचार करतात. हे एक अगदी सोपी डेटा मॉडेल आहे, परंतु ते काही मूलभूत संकल्पनांचे प्रतिनिधित्व करते, जिथे विकसक किंवा अगदी व्यवसाय विश्लेषक किंवा व्यवसाय वापरकर्त्यांनी कदाचित त्या भिन्न वस्तू किंवा व्यवसाय संकल्पना म्हणून विचार करू शकतात. आत्तापर्यंत याचे वर्गीकरण करणे खूप अवघड आहे परंतु आम्ही २०१ release च्या रिलीझमध्ये ईआर / स्टुडिओ एंटरप्राइझ टीम संस्करणात प्रत्यक्षात काय केले आहे, आपल्याकडे आता बिझनेस डेटा ऑब्जेक्ट्स नावाची संकल्पना आहे. आणि हे आम्हाला करण्यास अनुमती देते ते म्हणजे आपल्याला अस्तित्त्वात असलेल्या कंपन्यांचे गट किंवा सारण्या खर्या व्यवसायाच्या वस्तूंमध्ये घेण्याची परवानगी देते.
उदाहरणार्थ, या नवीन दृश्यावर आम्हाला जे मिळाले आहे ते म्हणजे खरेदी ऑर्डर हेडर आणि ऑर्डर लाइन आता एकत्रितपणे ओढली गेली आहेत, ते ऑब्जेक्ट म्हणून एन्केप्युलेटेड आहेत, डेटा चालू ठेवल्यास आम्ही त्यांच्या कार्याचे एकक म्हणून विचार करू , आणि आम्ही त्यांना एकत्र आणत आहोत जेणेकरून आता हे वेगवेगळ्या प्रेक्षकांशी संबधित करणे खूप सोपे आहे. ते संपूर्ण मॉडेलिंग वातावरणात पुन्हा वापरण्यायोग्य असतात. ते फक्त एक रेखांकन बांधकाम नव्हे तर एक वास्तविक ऑब्जेक्ट आहेत परंतु आम्हाला आणखी एक फायदा आहे की जेव्हा आम्ही प्रत्यक्षात मॉडेलिंगच्या दृष्टीकोनातून संवाद साधतो तेव्हा आपण निवडकपणे कोसळू शकतो किंवा त्यांचा विस्तार करू शकतो जेणेकरून आम्ही विशिष्ट भागधारक प्रेक्षकांसह संवादांसाठी संक्षिप्त दृष्टिकोन तयार करू शकू, तांत्रिक प्रेक्षकांसाठी आपण जसे पहात आहोत तसे आम्ही अधिक तपशीलवार दृश्य देखील ठेवू शकतो. हे खरोखर आम्हाला संप्रेषणाचे खरोखर चांगले वाहन देते. आम्ही आता जे पाहत आहोत ते विविध प्रकारचे मॉडेल प्रकार एकत्रित करीत आहे, त्यांना व्यवसाय डेटा ऑब्जेक्ट्सच्या संकल्पनेसह वाढवित आहे, आणि आता मी या प्रकारच्या गोष्टींना वास्तविकपणे आणखी काही अर्थ कसे वापरावे आणि आम्ही आमच्यात एकत्र कसे जोडतो याबद्दल बोलणार आहे. एकूण वातावरण.
मी येथे माझे वेबएक्स परत शोधण्याचा प्रयत्न करीत आहे जेणेकरून मी ते करण्यास सक्षम आहे. आणि तिथे आम्ही परत हॉट टेक स्लाइड्सवर जाऊ. मी येथे काही स्लाइड्स वेगवानपणे पुढे पाठवणार आहे कारण आपण या मॉडेलच्या प्रात्यक्षिकातच यापूर्वी पाहिले आहे. मला नामकरण करण्याच्या मानकांबद्दल खूप लवकर बोलू इच्छित आहे. आम्हाला वेगवेगळे नामांकन लागू करणे आणि अंमलात आणण्याची इच्छा आहे. आपल्याला काय करायचे आहे ते आहे की आमच्या मूळात शब्दांच्या किंवा वाक्यांशांमधून किंवा संक्षिप्त भाषेतून मूळ अर्थ काढण्यासाठी आमच्या रेपॉजिटरीमध्ये नेमिंग स्टँडर्ड टेम्पलेट्स साठवण्याची आणि इंग्रजी प्रकारच्या अर्थपूर्ण शब्दाशी बांधून ठेवण्याची क्षमता आमच्यात आहे. आम्ही व्यवसाय अटी, प्रत्येकासाठी संक्षिप्त रूपे वापरणार आहोत आणि आम्ही ऑर्डर, प्रकरणे निर्दिष्ट करू आणि उपसर्ग आणि प्रत्यय जोडू. यासाठी विशिष्ट उपयोग प्रकरण सामान्यत: जेव्हा लोक लॉजिकल मॉडेल तयार करीत असतात आणि प्रत्यक्षात एखादे भौतिक मॉडेल तयार करण्यास पुढे जात असतात जेथे ते संक्षेप आणि इतर सर्व काही वापरत असतील.
सुंदर गोष्ट म्हणजे ती तितकीच शक्तिशाली, उलटपक्षी अधिक सामर्थ्यवान, जर आम्ही त्या नामांकित मानकांपैकी काही आम्ही प्रत्यक्ष अभियांत्रिकी केलेल्या काही भौतिक डेटाबेसवर काय असल्याचे सांगितले तर ते संक्षिप्त रूप आपण घेऊ शकतो, त्यांना अधिक काळ बदलू शकतो. शब्द आणि त्यांना इंग्रजी वाक्ये मध्ये परत आणा. आपला डेटा कसा दिसतो यासाठी आम्ही आता योग्य नावे मिळवू शकतो. मी म्हटल्याप्रमाणे, टिपिकल यूज केस म्हणजे आपण फिजिकल ते लॉजिकल पुढे जाऊ आणि डेटा स्टोअर्स आणि त्या प्रकारच्या वस्तूंचा नकाशा बनवू. आपण उजवीकडील स्क्रीनशॉट पाहिले तर आपल्याला दिसेल की स्त्रोत नावे वरून संक्षिप्त नावे आहेत आणि जेव्हा आम्ही नामांकन मानके टेम्पलेट लागू करतो तेव्हा आम्हाला अधिक पूर्ण नावे मिळाली आहेत. आम्ही वापरत असलेल्या नेमिंग स्टँडर्ड टेम्पलेटच्या आधारावर, आम्ही इच्छित असल्यास त्यामध्ये रिक्त स्थान आणि त्यासारख्या सर्व गोष्टी ठेवू शकतो. आम्ही हे आमच्या मॉडेल्समध्ये आणू इच्छितो परंतु आम्ही ते पाहू शकतो. जेव्हा आपल्याला एखाद्या गोष्टीस काय म्हणतात हे माहित असते तेव्हाच आपण त्यास परिभाषा जोडण्यास सुरवात करू शकतो, कारण हे काय आहे हे आपल्याला माहित नसल्यास आपण त्यास अर्थ कसे लागू करू शकतो?
छान गोष्ट अशी आहे की जेव्हा आम्ही सर्व प्रकारच्या गोष्टी करत असतो तेव्हा आपण वास्तविकपणे हे बोलू शकतो. मी रिव्हर्स इंजिनियरिंगबद्दल बोललो, आम्ही रिव्हर्स इंजिनियरिंग करत असताना आम्ही एकाच वेळी नेमिंग टेम्पलेटची नावे मागवू शकतो. विझार्डच्या एका चरणात आपण काय करू शकतो, अधिवेशने काय आहेत हे जर आपल्याला माहित असेल तर आपण अभियांत्रिकीचा भौतिक डेटाबेस उलटा करू शकतो, हे मॉडेलिंग वातावरणात भौतिक मॉडेल म्हणून परत आणणार आहे. त्या नामकरण संमेलने लागू करणार म्हणून आम्ही पर्यावरणातील संबंधित तार्किक मॉडेलमध्ये इंग्रजी सारख्या नावे काय दर्शवितो ते पाहू. आम्ही हे करू देखील शकतो आणि हे एक्सएमएल स्कीमा पिढीसह एकत्र करू शकतो जेणेकरुन आपण एक मॉडेल घेऊ आणि आमच्या संक्षेपांसह ते पुढे ढकलू, जरी आम्ही एसओए फ्रेमवर्क किंवा त्या प्रकारच्या वस्तूचा वापर करत असू, तर मग आम्ही वेगवेगळ्या नामांकन संमेलनांना पुढे आणू शकू. आम्ही खरोखर मॉडेलमध्येच साठवले आहे. हे आम्हाला खूप शक्तिशाली क्षमता देते.
पुन्हा, माझ्याकडे टेम्पलेट असल्यास हे कसे दिसावे याचे एक उदाहरण येथे आहे. हे खरोखर दर्शवित आहे की माझ्याकडे नामांकन मानदंडांच्या अधिवेशनात “कर्मचारी,” एसएएल “पगारासाठी,” पीएलएन “ईएमपी’ असा होता. मी मॉडेल्स तयार करत असताना आणि गोष्टी ठेवत असताना त्यांना संवादात्मक रीतीने चालविण्यासाठी मी त्यांना लागू देखील करु शकतो. जर मी हा संक्षेप वापरत असतो आणि घटकाच्या नावावर मी "कर्मचारी वेतन योजना" टाइप करतो, तर ते नामांकन मानकांच्या टेम्पलेटसह कार्य करेल मी येथे परिभाषित केले आहे, जेव्हा मी घटक तयार करीत होते तेव्हा त्यांनी मला EMP_SAL_PLN दिले असते आणि तत्काळ मला संबंधित भौतिक नावे दिली आहेत.
पुन्हा, आम्ही अभियांत्रिकी डिझाइन करताना आणि अग्रेषित करतो तेव्हा खूप चांगले. आमच्याकडे एक अतिशय अनोखी संकल्पना आहे आणि येथूनच आपण खरोखरच या वातावरणात एकत्र आणू लागतो.आणि याला युनिव्हर्सल मॅपिंग्स म्हणतात. एकदा आम्ही या सर्व मॉडेल्सला आपल्या वातावरणात आणल्यानंतर आम्ही काय करण्यास सक्षम आहोत असे गृहीत धरुन की आम्ही आता या नामकरण पद्धती लागू केल्या आहेत आणि त्या सापडणे सोपे आहे, आता आपण ईआरमध्ये युनिव्हर्सल मॅपींग्ज नावाचे बांधकाम वापरू शकतो. / स्टुडिओ. आम्ही मॉडेल्समध्ये घटकांना लिंक करू शकतो. जेथे जेथे आम्ही "ग्राहक" पाहतो - आपल्याकडे बर्याच सिस्टम आणि बर्याच वेगवेगळ्या डेटाबेसमध्ये "ग्राहक" असू शकतात - आम्ही त्या सर्वांना एकत्र जोडण्यास सुरवात करू जेणेकरून मी जेव्हा एका मॉडेलमध्ये कार्य करीत असतो तेव्हा I इतर मॉडेल्समधील ग्राहकांचे प्रकटीकरण कोठे आहेत ते पाहू शकता. आम्हाला हे दर्शविणारे मॉडेल लेयर मिळालेले असल्याने आम्ही डेटा स्रोतांमध्ये ते बांधू शकतो आणि आमच्या डेटाबेसमध्ये कोणत्या डेटाबेसमध्ये असतो याचा वापर केला जातो. हे खरोखर खूप एकत्रितपणे एकत्र बांधण्याची क्षमता देते.
मी आपल्याला व्यवसाय डेटा ऑब्जेक्ट दर्शविले आहेत. मला मेटाडेटा विस्ताराबद्दल देखील बोलायचे आहे, ज्यास आम्ही संलग्नक म्हणतो. हे आपल्या मॉडेल ऑब्जेक्ट्ससाठी अतिरिक्त मेटाडेटा तयार करण्याची क्षमता देते. बर्याचदा मी डेटा गव्हर्नन्स आणि डेटा क्वालिटीच्या दृष्टीकोनातून बर्याच गोष्टी काढून टाकण्यासाठी आणि मास्टर डेटा मॅनेजमेन्ट आणि डेटा रीटेन्शन पॉलिसीसाठी मदत करण्यासाठी मी या प्रकारच्या गुणधर्मांची स्थापना करतो. मूळ कल्पना ही आहे की आपण ही वर्गीकरणे तयार करीत आहात आणि टेबल पातळीवर, स्तंभ स्तरावर, अशा प्रकारच्या गोष्टी आपण इच्छिता तेथे त्यास संलग्न करू शकता. सर्वात सामान्य वापर प्रकरण म्हणजे, घटक म्हणजे सारण्या असतात आणि मग मी परिभाषित करू शकतो: माझे मास्टर डेटा ऑब्जेक्ट्स काय आहेत, माझे संदर्भ टेबल काय आहेत, माझे ट्रान्झॅक्शनल टेबल्स काय आहेत? डेटा गुणवत्तेच्या दृष्टीकोनातून मी व्यवसायाच्या दृष्टीने महत्त्वपूर्णतेनुसार वर्गीकरण करू शकतो जेणेकरून आम्ही डेटा साफ करण्याच्या प्रयत्नांना आणि त्या प्रकारच्या गोष्टीस प्राधान्य देऊ शकू.
बर्याचदा दुर्लक्षित केले जाणारे काहीतरी म्हणजे, आमच्या संस्थेतील डेटाच्या विविध प्रकारांसाठी धारणा धोरण काय आहे? आम्ही हे सेट करू शकतो आणि आम्ही त्यांना आमच्या मॉडेलिंग वातावरणात आणि अर्थातच आमच्या भांडारातील विविध प्रकारच्या माहितीच्या कलाकृतींशी संलग्न करू शकतो. सौंदर्य म्हणजे, हे आमच्या डेटा डिक्शनरीमध्ये अटॅचमेंट्स लाइव्ह आहेत म्हणूनच जेव्हा आम्ही वातावरणात एंटरप्राइझ डेटा शब्दकोष वापरत असतो, तेव्हा आम्ही त्यांना एकाधिक मॉडेलमध्ये संलग्न करू शकतो. आम्हाला फक्त एकदाच त्यांना परिभाषित करावे लागेल आणि आम्ही आमच्या वातावरणातील निरनिराळ्या मॉडेल्सवर त्यांना वारंवार पुन्हा फायदा करु शकतो. हे दर्शविण्यासाठी हा फक्त एक द्रुत स्क्रीनशॉट आहे जेव्हा आपण एखादे संलग्नक करता तेव्हा आपण निर्दिष्ट करू शकता, त्यास जोडलेले सर्व तुकडे काय आहेत. आणि हे उदाहरण येथे मूल्यांची सूची आहे, म्हणून जेव्हा ते आत जातात तेव्हा आपण मूल्यांच्या सूचीमधून निवडू शकता, मॉडेलिंगच्या वातावरणामध्ये काय निवडले जाते यावर आपल्याकडे बरेच नियंत्रण असते आणि आपण डीफॉल्ट काय सेट करू शकता मूल्य निवडले नाही तर मूल्य आहे. तर तिथे बरीच शक्ती. ते डेटा शब्दकोशात राहतात.
या स्क्रीनवर मी तुम्हाला थोडेसे खाली दर्शवू इच्छित आहे, याव्यतिरिक्त आपण वरच्या भागामध्ये संलग्नकांचे प्रकार दर्शवित आहात, त्या खाली आपल्याला डेटा सुरक्षा माहिती दिसते. आम्ही खरोखरच पर्यावरणातील माहितीच्या विविध भागांवर डेटा सुरक्षा धोरणे लागू करू शकतो. भिन्न अनुपालन मॅपिंगसाठी, डेटा सुरक्षा वर्गीकरणासाठी, आम्ही त्यापैकी बरेच काही बॉक्समधून बाहेर पाठवितो जे आपण नुकतेच व्युत्पन्न आणि वापरण्यास प्रारंभ करू शकता परंतु आपण आपले स्वतःचे अनुपालन मॅपिंग आणि मानक देखील परिभाषित करू शकता. आपण HIPAA करत असाल किंवा तेथे इतर कोणत्याही पुढाकार घेत असाल. आणि आपण खरोखरच आपल्या वातावरणात मेटाडाटाचा हा समृद्ध सेट तयार करणे सुरू करू शकता.
आणि नंतर पारिभाषिक शब्दावली आणि अटी - येथे असा आहे की व्यवसायाचा अर्थ जोडला गेला आहे. आमच्याकडे बरेचदा डेटा शब्दकोश असतात जे बरेचदा एखादी संस्था शब्दकोष बाहेर काढण्यासाठी प्रारंभ बिंदू म्हणून वापरत असते, परंतु संज्ञा आणि शब्दसंग्रह बर्याचदा तांत्रिक. तर आपण काय करू शकतो, आपली इच्छा असल्यास, शब्दावली काढण्यासाठी त्यास प्रारंभ बिंदू म्हणून वापरू शकतो, परंतु व्यवसाय खरोखरच आपल्या मालकीचा असावा अशी आमची इच्छा आहे. आम्ही कार्यसंघ सर्व्हर वातावरणात काय केले आहे ते म्हणजे आम्ही लोकांना व्यवसाय परिभाषा तयार करण्याची क्षमता दिली आहे आणि त्यानंतर आम्ही त्यांना मॉडेलिंगच्या वातावरणात ज्या वेगवेगळ्या मॉडेल कलाकृतींचा परस्पर संबंध साधू शकतो त्यांच्याशी दुवा साधू शकतो. यापूर्वी आपण चर्चा केलेला मुद्दा देखील ओळखतो जो म्हणजे आपण जितके जास्त लोक टाइप करीत आहात तितकेच मानवी चुकांची शक्यता असते. आमच्या शब्दावधी संरचनेत आपण काय करतो ते म्हणजे एक, आम्ही शब्दकोष एका श्रेणीबद्धतेचे समर्थन करतो, म्हणून आपल्याकडे संस्थेमध्ये वेगवेगळे शब्दकोष किंवा भिन्न प्रकारच्या वस्तू असू शकतात, परंतु महत्त्वाचे म्हणजे आपल्याकडे आधीपासूनच काही स्रोत असल्यास अटी आणि सर्वकाही परिभाषित केल्याशिवाय आम्ही हे आपल्या मॉडेलिंग वातावरणामध्ये आणि आमच्या कार्यसंघाच्या सर्व्हरला किंवा आमच्या शब्दकोशात आणण्यासाठी सीएसव्ही आयात करू शकतो आणि तेथून दुवा साधण्यास सुरवात करतो. आणि प्रत्येक वेळी जेव्हा काहीतरी बदलले जाते तेव्हा प्रतिमांच्या आधी आणि नंतरच्या परिभाषांनुसार आणि इतर सर्व गोष्टी कशा होत्या याचा एक संपूर्ण ऑडिट माग आहे आणि आपण अगदी नजीकच्या काळात जे येत आहात ते देखील अधिकृतता वर्कफ्लो आहे म्हणून आम्ही कार्यवाही करत असताना, समित्या किंवा व्यक्तींकडून मंजूर झालेल्या गोष्टी आणि या प्रकारची नियंत्रणे आम्ही पुढे जाताना प्रशासनाची प्रक्रिया अधिक मजबूत बनवू शकतो.
आमच्या कार्यसंघाच्या सर्व्हर शब्दकोषात जेव्हा आमच्याकडे या शब्दकोष संज्ञा असतात तेव्हा हे आपल्यासाठी देखील करते, मी येथे आणलेल्या मॉडेलमध्येच अस्तित्वातील संपादनाचे हे एक उदाहरण आहे. यात कदाचित दुवा साधला गेला असेल, परंतु आम्ही काय करतो जर त्या शब्दकोशामध्ये असे शब्द आहेत जे येथे आपल्या संस्थांमधील नोट्स किंवा वर्णनात आढळतात, तर त्या आपोआप हलके हायपरलिंक्ड रंगात दर्शविल्या गेल्या आहेत आणि जर आपण त्यावरील माऊस, आम्ही व्यवसायातील शब्दकोशापासून प्रत्यक्षातली व्याख्या पाहू शकतो. जेव्हा आम्ही माहिती स्वतःच वापरत असतो तेव्हा त्या आमच्याकडे असलेल्या सर्व शब्दकोषांसह ही अधिक समृद्ध माहिती देखील देते. हे खरोखर अनुभव समृद्ध करण्यास आणि आम्ही कार्य करीत असलेल्या प्रत्येक गोष्टीचा अर्थ लावण्यास खरोखर मदत करते.
तर पुन्हा ते खूप जलद उड्डाणपूल होते. अर्थात आम्ही वेगवेगळे भाग शोधत असताना आम्ही यावर काही दिवस घालवू शकलो, परंतु हे पृष्ठभागावर एक द्रुत उड्डाणपूल आहे. आम्ही जटिल प्रयत्नांची पराकाष्ठा करीत आहोत जे त्या जटिल डेटा वातावरणासारखे दिसते. आम्ही त्या सर्व डेटा कृत्रिमतांचे दृश्यमानता सुधारित करू आणि ईआर / स्टुडिओसह त्यांना काढून टाकण्यासाठी सहयोग करू इच्छितो. आम्हाला अधिक कार्यक्षम आणि स्वयंचलित डेटा मॉडेलिंग सक्षम करायचे आहेत. आणि हा आपण सर्व प्रकारच्या डेटाविषयी बोलतो आहोत, हा मोठा डेटा असो, पारंपारिक रिलेशनल डेटा, कागदजत्र स्टोअर किंवा इतर काहीही. आणि पुन्हा आम्ही ते साध्य केले कारण आमच्याकडे भिन्न प्लॅटफॉर्म आणि आपण तेथे असलेल्या इतर साधनांसाठी प्रभारी फॉरवर्ड आणि रिव्हर्स अभियांत्रिकी क्षमता आहेत. आणि हे सामील असलेल्या सर्व भागधारकांसह संघटनेत सामायिक करणे आणि संप्रेषण करण्यासारखे आहे. येथे आम्ही नामकरण मानकांद्वारे अर्थ लागू करतो. त्यानंतर आम्ही आमच्या व्यवसायातील शब्दकोषांद्वारे परिभाषा लागू करतो. आणि मग आम्ही आमच्या इतर सर्व प्रशासकीय क्षमतांसाठी मेटाडेटा विस्तारांसह डेटा गुणवत्ता विस्तार, मास्टर डेटा व्यवस्थापनासाठी वर्गीकरण किंवा आपण त्या डेटावर लागू करू इच्छित वर्गीकरणाच्या कोणत्याही इतर प्रकारांसह पुढील वर्गीकरण करू शकतो. आणि मग आम्ही पुढील सारांश करू आणि व्यवसाय डेटा ऑब्जेक्टसह संप्रेषण आणखी वाढवू शकतो, विशेषत: मॉडेलर्स आणि विकसकांमधील भिन्न भागधारक प्रेक्षकांसह.
आणि पुन्हा, या बद्दल जे महत्त्वाचे आहे ते आहे, त्या सर्वांच्या मागे एक अतिशय मजबूत बदल क्षमता क्षमता असलेले एकात्मिक भांडार आहे. आज मला ते दर्शवायला वेळ मिळाला नाही कारण तो बर्यापैकी गुंतागुंतीचा झाला आहे, परंतु भांडारात व्यवस्थापन व्यवस्थापनाची क्षमता आणि लेखापरीक्षण खुप मजबूत आहे. आपण नामांकित प्रकाशने करू शकता, आपण नामांकित आवृत्त्या करू शकता आणि आपल्यात बदल करण्याची क्षमता असलेल्या आपल्यासाठी क्षमता देखील आहे, आम्ही ते आपल्या कार्यात बांधू शकतो. विकसक जसे की त्यांचे कोड बदल कार्य करतात तसेच वापरकर्त्याच्या कथांशी देखील कार्य करतात त्याप्रमाणेच कार्ये आपल्या मॉडेलमधील बदलांना कार्यांसह जोडण्याची आणि कार्य करण्याची आमची क्षमता आज आहे.
पुन्हा, हे एक द्रुत विहंगावलोकन होते. मला आशा आहे की तुमची भूक वाढविणे पुरेसे आहे जेणेकरून आम्ही भविष्यात पुढे जात असताना यापैकी काही विषयांचे विभाजन करण्याबद्दल अधिक सखोल संभाषणात मग्न होऊ. आपल्या वेळेबद्दल धन्यवाद, आणि परत रेबेका.
रेबेका जोझवियाक: धन्यवाद, रॉन, ते आश्चर्यकारक होते आणि मला प्रेक्षकांकडून काही प्रश्न आहेत, परंतु आपण काय म्हणायचे आहे याबद्दल मी आमच्या विश्लेषकांना त्यांचे दात बुडवण्याची संधी देऊ इच्छित आहे. एरिक, मी पुढे जात आहे आणि कदाचित आपणास या स्लाइडला किंवा एखादे वेगळी पत्ता सांगायचा असेल तर तुम्ही पुढे का जात नाही? किंवा इतर कोणताही प्रश्न.
एरिक लिटल: नक्की. क्षमस्व, प्रश्न काय होता रेबेका? आपण मला विशिष्ट काहीतरी विचारू इच्छित आहात की…?
रेबेका जोझवियाक: मला माहित आहे की आपल्याकडे रॉनसाठी प्रारंभी काही प्रश्न होते. आपण आता त्यास यापैकी काही, किंवा त्यापैकी काहींना आपल्या स्लाइडवरून किंवा आपण विचारू इच्छित असलेले हितसंबंध लपविणार्या इतर कोणत्याही गोष्टीकडे लक्ष देण्यास सांगायचे असल्यास, IDERA च्या मॉडेलिंग कार्यक्षमतेबद्दल.
एरिक लिटल: होय, म्हणून एक गोष्ट, रॉन, मग तुम्ही लोकांनो, असे दिसते की आपण दर्शवित असलेल्या आकृत्या सर्वसाधारणपणे अस्तित्वातील संबंध आकृती आहेत जसे की आपण सामान्यपणे डेटाबेस बांधकाम वापरता, बरोबर?
रॉन हुईझेन्गा: होय, सामान्यत: बोलणे, परंतु आपल्याकडे कागदजत्र स्टोअरसाठी विस्तारित प्रकार आणि त्या प्रकारच्या वस्तू देखील आहेत. आम्ही फक्त निव्वळ रिलेशनल नोटेशनपासून भिन्न आहोत, आम्ही त्या इतर स्टोअरसाठी देखील अतिरिक्त नोट्स जोडल्या आहेत.
एरिक लिटल: आपण लोक ग्राफिक-आधारित प्रकारच्या मॉडेलिंगचा एखादा मार्ग वापरू शकता, यासाठी समाकलित करण्याचा एक मार्ग आहे, उदाहरणार्थ, समजा, माझ्याकडे काही वरचे चतुष्कोण, टॉपब्रेड संगीतकार साधन आहे किंवा मी प्रोटोगे मध्ये काहीतरी केले आहे किंवा , तुम्हाला माहिती आहे, एफआयबीओ मधील वित्तीय लोकांप्रमाणेच, ते सिमेंटिक्समध्ये बरेच काम करीत आहेत, आरडीएफ सामग्री - अशा प्रकारचे अस्तित्व-संबंध ग्राफ प्रकारातील मॉडेलिंग या उपकरणात आणण्याचा आणि त्याचा उपयोग करण्याचा एक मार्ग आहे?
रॉन हुईझेन्गा: आम्ही ग्राफ कसे हाताळू शकतो हे आम्ही पहात आहोत. आम्ही आज स्पष्टपणे आलेख डेटाबेस आणि त्या प्रकारची वस्तू हाताळत नाही आहोत, परंतु आपला मेटाडेटा वाढवण्यासाठी आम्ही ते करू शकतो असे मार्ग शोधत आहोत. म्हणजे, आम्ही XML आणि त्या प्रकारच्या गोष्टी आत्ताच गोष्टी आणू शकतो, जर आपण प्रारंभिक बिंदू म्हणून आणण्यासाठी कमीतकमी एक्सएमएलची एखादी व्याख्याने देऊ शकलो तर. परंतु आम्ही ते आणण्यासाठी आणखी मोहक मार्ग शोधत आहोत.
आम्ही देखील आपल्याकडे असलेल्या रिव्हर्स इंजिनीअरिंग पुलांची यादी देखील दाखविली आहे, म्हणून आम्ही विशिष्ट प्लॅटफॉर्मवर त्या पुलांना विस्तार मिळविण्याकडे नेहमीच पहात असतो. या निरनिराळ्या नव्या बांधकामे आणि तेथील वेगवेगळ्या प्लॅटफॉर्मवर आलिंगन देणे, हे एक निरंतर, चालू असलेले प्रयत्न आहे. पण मी म्हणू शकतो की हे करण्यापासून आम्ही नक्कीच आघाडीवर आहोत. उदाहरणार्थ मी जी सामग्री दाखविली आहे, उदाहरणार्थ, मोंगोडीबी आणि त्या प्रकारची, आम्ही आमच्या स्वत: च्या उत्पादनात मूळपणे हे करण्यासाठी प्रथम डेटा मॉडेलिंग विक्रेता आहोत.
एरिक लिटल: ठीक आहे, होय. तेव्हा मी तुमच्यासाठी केलेला दुसरा प्रश्न, कारभार आणि देखभाल या दृष्टीने होता - जसे की जेव्हा तुम्ही उदाहरण वापरले तेव्हा तुम्ही “कर्मचारी” असलेल्या व्यक्तीचे उदाहरण सांगितले तेव्हा मला वाटते की ते “ पगार "आणि नंतर आपल्याकडे एक" योजना "आहे, आपण कसे व्यवस्थापित करता, उदाहरणार्थ, विविध प्रकारचे लोक ज्यात असू शकतात - समजा आपल्याकडे एक मोठे आर्किटेक्चर आहे, तर समजा, आपल्याकडे एक मोठा उद्योग आहे आणि लोक या साधनात गोष्टी एकत्र आणू लागतात आणि येथे तुमचा एक गट आला आहे ज्यामध्ये “कर्मचारी” हा शब्द आहे आणि येथे एक गट ज्याला “कामगार” हा शब्द आहे. आणि इथला एक माणूस “पगार” म्हणतो आणि दुसरा माणूस म्हणतो “वेतन”
आपण लोक या प्रकारच्या भेदांमध्ये कसा समेट साधता आणि व्यवस्थापित करता आणि नियंत्रित करता? कारण ग्राफच्या जगात आम्ही हे कसे करू हे मला माहित आहे, आपल्याला माहित आहे की आपण समानार्थी याद्या वापरत असाल किंवा आपण असे म्हणू शकता की तेथे एक संकल्पना आहे आणि त्यामध्ये अनेक गुणधर्म आहेत, किंवा आपण एसकेओएस मॉडेलमध्ये म्हणू शकता की माझ्याकडे प्राधान्यकृत लेबल आहे आणि माझ्याकडे आहे मी वापरू शकतो असंख्य वैकल्पिक लेबल. तुम्ही लोक ते कसे करतात?
रॉन हुईझेन्गा: आम्ही हे दोन वेगवेगळ्या मार्गांनी करतो आणि प्रामुख्याने प्रथम संज्ञेबद्दल बोलूया. अर्थात आम्ही करतो त्यापैकी एक म्हणजे आम्हाला परिभाषित किंवा मंजूर अटी आणि व्यवसायातील शब्दकोष म्हणजे आपल्याला जिथे पाहिजे असेल तिथे आहे. आणि आम्ही व्यवसायातील शब्दकोशामध्ये समानार्थी शब्दांच्या दुव्यास अनुमती देतो जेणेकरुन आपण काय करू शकता असे म्हणू शकता, येथे माझी संज्ञा आहे, परंतु त्याकरिता सर्व प्रतिशब्द काय आहेत हे देखील आपण परिभाषित करू शकता.
आता नक्कीच एक मनोरंजक गोष्ट म्हणजे जेव्हा आपण या सर्व वेगवेगळ्या प्रणालींसह या विस्तृत डेटा लँडस्केपकडे पहात आहात तेव्हा आपण तेथे जाऊ शकत नाही आणि संबंधित सारण्या आणि त्या प्रकारच्या गोष्टी बदलू शकत नाही त्या नेमिंग स्टँडर्डशी संबंधित कारण आपण विकत घेतलेले पॅकेज असू शकते, त्यामुळे डेटाबेस किंवा काहीही बदलण्यावर आपले नियंत्रण नाही.
आम्ही तिथे काय करू शकतो, शब्दकोष परिभाषा संबद्ध करण्यास सक्षम असण्याव्यतिरिक्त, त्या सार्वभौम मॅपिंगद्वारे ज्याबद्दल मी बोललो, त्याद्वारे आपण काय करू, आणि कोणत्या प्रकारचे शिफारस केलेले दृष्टिकोन आहे, त्यास एक अतिरंजित लॉजिकल मॉडेल दिले गेले आहे या भिन्न व्यवसाय संकल्पना म्हणजे आपण बोलत आहात. त्यामध्ये व्यवसायाच्या शब्दकोष अटी जोडा आणि आता छान गोष्ट म्हणजे आपल्याकडे हे बांधकाम आहे जे लॉजिकल अस्तित्वाचे प्रतिनिधित्व करते जसे की, आपण त्या लॉजिकल अस्तित्वापासून त्या लॉजिकल अस्तित्वाच्या सर्व अंमलबजावणीशी जोडणे प्रारंभ करू शकता. विविध प्रणाली.
मग जिथे आपल्याला त्याची आवश्यकता आहे तेथे आपण पाहू शकता अरे, “व्यक्ती” या प्रणालीत “कर्मचारी” असे म्हणतात. येथील इतर पगारामध्ये “पगार” याला “वेतन” म्हणतात. कारण आपण ते पाहिले आहे, त्या सर्वांचे भिन्न स्वरुप आपल्याला दिसेल कारण आपण त्यांचा दुवा साधला आहे.
एरिक लिटल: ठीक आहे, हो, समजले. त्या अर्थाने, असे म्हणणे काही सुरक्षित आहे की काही प्रकारचे ऑब्जेक्ट देणारं दृष्टीकोन?
रॉन हुईझेन्गा: काहीसे. हे त्यापेक्षा थोडे अधिक गहन आहे, मला वाटते आपण म्हणू शकाल. म्हणजे, आपणास व्यक्तिशः जोडणे आणि त्याद्वारे जाणे आणि तपासणी करणे आणि त्या सर्वांचे परीक्षण करण्याचा दृष्टिकोन देखील असू शकतो. ज्या गोष्टींबद्दल मला बोलण्याची खरोखरच संधी मिळाली नाही - कारण पुन्हा आमच्याकडे बर्याच क्षमता आहेत - आमच्याकडे देखील डेटा आर्किटेक्ट टूलमध्ये पूर्ण ऑटोमेशन इंटरफेस आहे. आणि एक मॅक्रो क्षमता, जी टूलमधील खरोखर प्रोग्रामिंग भाषा आहे. म्हणून आम्ही प्रत्यक्षात मॅक्रो लिहा अशा गोष्टी करू शकतो, त्या बाहेर जाऊन गोष्टींची चौकशी करा आणि आपल्यासाठी दुवे तयार करा. आम्ही ती माहिती आयात आणि निर्यात करण्यासाठी वापरतो, आम्ही ती वस्तू बदलण्यासाठी किंवा विशेषता जोडण्यासाठी वापरू शकतो, मॉडेलमध्येच इव्हेंट, किंवा आम्ही बॅचमध्ये चालण्यासाठी आणि वस्तू चौकशीसाठी आणि प्रत्यक्षात भिन्न बांधकामे तयार करण्यासाठी वापरू शकतो. मॉडेल. तर तेथे एक संपूर्ण ऑटोमेशन इंटरफेस आहे ज्याचा लोक देखील फायदा घेऊ शकतात. आणि त्यासह युनिव्हर्सल मॅपिंग्ज वापरणे हे एक अतिशय शक्तिशाली मार्ग असेल.
रेबेका जोझवियाक: ठीक आहे, धन्यवाद रॉन, आणि एरिकचे आभार. ते उत्तम प्रश्न होते. मला माहित आहे की आम्ही आता अगदी शेवटच्या टप्प्यातून चालत आहोत, पण मला माल्कमला रॉनच्या मार्गावर काही प्रश्न फेकण्याची संधी द्यायची आहे. मॅल्कम?
मॅल्कम चिशोलम: धन्यवाद, रेबेका. तर, रॉन, हे खूपच मनोरंजक आहे, मला बर्याच क्षमता येथे आहेत. मला ज्या क्षेत्रामध्ये रस आहे ज्यापैकी एक म्हणजे, आमच्याकडे विकास प्रकल्प असल्यास ते सांगा, आपण या क्षमतांचा वापर करून डेटा मॉडेलर कसे पहाल आणि डेटा प्रोफाईलरसह डेटा विश्लेषकांसह, व्यवसाय विश्लेषकांसह अधिक सहकार्याने कार्य कसे करता ते पाहू शकता. , आणि शेवटी प्रकल्पातील वास्तविक माहिती आवश्यकतांसाठी जबाबदार असणार्या व्यवसाय प्रायोजकांसह. आम्ही पहात असलेल्या क्षमतेसह डेटा मॉडेलर खरोखर आपल्यास कसे माहित आहे की हा प्रकल्प अधिक प्रभावी आणि कार्यक्षम कसा बनवेल?
रॉन हुईझेन्गा: मला असे वाटते की आपण तेथे करण्याच्या गोष्टींपैकी एक म्हणजे एक डेटा मॉडेलर आहे - आणि माझे असे काही मॉडेलर्स निवडण्याचे नाही, परंतु मी तरीही असे करीन - काही लोकांना अजूनही डेटा मॉडेलरचा असा समज आहे हा खरोखर द्वारपालासारख्या भूमिकेचा प्रकार आहे, आम्ही हे कसे कार्य करते ते परिभाषित करीत आहोत, आम्ही पहारेकरी आहोत जे सर्व काही बरोबर आहे याची खात्री करतात.
आता त्या पैलूचा एक पैलू आहे की आपण ध्वनी डेटा आर्किटेक्चर आणि इतर सर्व काही परिभाषित करत आहात हे सुनिश्चित करा. परंतु सर्वात महत्वाची गोष्ट म्हणजे डेटा मॉडेलर म्हणून - आणि जेव्हा मी सल्लामसलत करीत होतो तेव्हा मला हे अगदी स्पष्टपणे आढळले - आपल्याला एक सुविधादार बनले पाहिजे आहे, म्हणून आपल्याला या लोकांना एकत्र खेचले पाहिजे.
हे यापुढे डिझाइन बनणार नाही, तयार कराल आणि डेटाबेस तयार कराल - आपल्याला जे करण्यास सक्षम असणे आवश्यक आहे ते सर्व या भिन्न भागधारक गटांसह कार्य करण्यास सक्षम असणे आवश्यक आहे, उलट अभियांत्रिकी करणे, माहिती आयात करणे, असणे इतर लोक शब्दावली किंवा दस्तऐवजीकरण असोत, यासारख्या सर्व गोष्टींसह सहयोग करतात - आणि हे रेपॉजिटरीमध्ये खेचण्यासाठी, आणि संकल्पनांना भांडारात एकत्र जोडण्यासाठी आणि त्या लोकांसह कार्य करण्यास मदत करणारे व्हा.
हे खरोखर एक सहयोगी प्रकारचे वातावरण आहे जेथे कार्ये परिभाषणे किंवा अगदी चर्चा थ्रेड्सद्वारे किंवा आमच्या कार्यसंघ सर्व्हरमध्ये असलेल्या अशा प्रकारची वस्तू, ज्यात लोक खरोखर सहयोग करू शकतात, प्रश्न विचारू शकतात आणि अंतिम उत्पादनांमध्ये येऊ शकतात त्यांच्या डेटा आर्किटेक्चर आणि त्यांच्या संस्थेची आवश्यकता आहे. असे उत्तर दिले का?
मॅल्कम चिशोलम: होय, मी सहमत आहे. आपल्याला माहिती आहे, मला वाटते की सोयीचे कौशल्य असे काहीतरी आहे जे डेटा मॉडेलर्समध्ये खरोखरच इष्ट आहे. मी सहमत आहे की आम्ही नेहमीच ते पहात नाही, परंतु मला असे वाटते की ते आवश्यक आहे आणि मी असे सुचवितो की कधीकधी आपल्या कोपर्यात तुमचा डेटा मॉडेलिंग करत रहायचा असतो परंतु आपण इतर भागीदार गटांसह तेथे कार्य केले पाहिजे. किंवा आपण कार्य करीत असलेल्या डेटा वातावरणाची आपल्याला माहिती नाही आणि मला असे वाटते की परिणामी या मॉडेलचा त्रास होतो. पण ते फक्त माझे मत आहे.
रॉन हुईझेन्गा: आणि ते मनोरंजक आहे कारण आपण व्यवसायांवर आयटीपासून कसा दूर केला जातो याविषयी इतिहासाबद्दल यापूर्वी आपल्या स्लाइडमध्ये काहीतरी नमूद केले आहे कारण ते वेळेवर फॅशन आणि अशा प्रकारच्या गोष्टींमध्ये निराकरण करीत नाहीत.
हे अतिशय मनोरंजक आहे की माझ्या नंतरच्या सल्लामसलत मध्ये, उत्पादन व्यवस्थापक होण्यापूर्वी मी त्या आधी मागील दोन वर्षात केलेले बहुतेक प्रकल्प व्यवसायाने प्रायोजित केले होते, जिथे तो खरोखर व्यवसाय करीत होता आणि डेटा आर्किटेक्ट होते आणि मॉडेलर आयटीचा भाग नव्हते. आम्ही उद्योग-प्रायोजित गटाचा एक भाग होतो आणि उर्वरित प्रकल्प संघांसोबत काम करणारे सोयीचे म्हणून आम्ही तिथे होतो.
मॅल्कम चिशोलम: तर मला वाटते की हा एक अतिशय मनोरंजक मुद्दा आहे.मला वाटते की आम्ही व्यवसाय जगात एक बदल दिसू लागलो आहोत जेथे व्यवसाय विचारत आहे, किंवा कदाचित विचार करीत आहे, मी काय करतो यासारखी प्रक्रिया करत नाही, परंतु डेटा म्हणजे काय याबद्दल विचार करण्यास देखील सुरूवात केली आहे मी ज्यासह कार्य करीत आहे, माझ्या डेटाची आवश्यकता काय आहे, डेटा म्हणून मी कोणत्या डेटाचा व्यवहार करीत आहे आणि कोणत्या दृष्टिकोनातून त्या दृष्टिकोनास समर्थन देण्यासाठी आम्ही आयडीआरए उत्पादने आणि क्षमता प्राप्त करू शकतो आणि मला वाटते की अगदी व्यवसायाच्या गरजा देखील तरीही तो थोडासा वेगळाच आहे.
रॉन हुईझेन्गा: मी आपल्याशी सहमत आहे आणि मला असे वाटते की आम्ही ते अधिकाधिक त्या मार्गाने जात आहोत. आम्ही एक प्रबोधन पाहिले आहे आणि आपण डेटाच्या महत्त्वच्या बाबतीत यापूर्वी त्यास स्पर्श केला आहे. आम्ही आयटीच्या सुरुवातीस किंवा डेटाबेसच्या उत्क्रांतीत डेटाचे महत्त्व पाहिले, नंतर आपण जसे म्हणता तसे आम्ही या संपूर्ण प्रक्रिया व्यवस्थापन चक्रात प्रवेश केला - आणि प्रक्रिया अत्यंत महत्वाची आहे, तेथे मला चुकीचे वाटू नका - परंतु आता काय झाले आहे जेव्हा ते घडले तेव्हा डेटा प्रकारचे फोकस.
आणि आता डेटा खरोखरच केंद्रबिंदू असल्याचे संस्थांना समजले आहे. आम्ही आमच्या व्यवसायात करत असलेल्या प्रत्येक गोष्टीचे डेटा प्रतिनिधित्व करते म्हणून आम्हाला आपल्याकडे अचूक डेटा असल्याची खात्री करणे आवश्यक आहे की आम्हाला आपला निर्णय घेण्याची आवश्यकता असलेली योग्य माहिती मिळू शकेल. कारण सर्व काही परिभाषित प्रक्रियेद्वारे येत नाही. काही माहिती ही इतर गोष्टींचे उत्पादन आहे आणि आम्हाला अद्याप ते शोधण्यात सक्षम असणे आवश्यक आहे, त्याचा अर्थ काय आहे हे माहित असणे आवश्यक आहे आणि आम्ही आपला डेटा अधिक चांगल्या प्रकारे चालविण्यासाठी वापरू शकतो अशा ज्ञानामध्ये शेवटी आपल्याला दिसणारा डेटा भाषांतरित करण्यास सक्षम असणे आवश्यक आहे.
मॅल्कम चिशोलम: बरोबर, आणि आता मी ज्या दुसर्या क्षेत्राशी संघर्ष करीत आहे ते म्हणजे मी डेटा लाइफ सायकल म्हणतो ज्याला आहे, तुम्हाला माहिती आहे, जर आपण एखाद्या एंटरप्राइझमधून जाणा chain्या डेटा सप्लाय शृंखलाकडे लक्ष दिले तर आम्ही डेटा संपादन ने प्रारंभ करू किंवा डेटा कॅप्चर, जो डेटा प्रविष्टी असू शकतो परंतु तो तितकाच असू शकतो, मी काही डेटा विक्रेत्याकडून एंटरप्राइझच्या बाहेरील डेटा घेत आहे.
आणि मग डेटा कॅप्चरवरून आम्ही डेटा देखभाल करण्यासाठी जातो जेथे मी हा डेटा प्रमाणित करण्याचा आणि ज्या ठिकाणी आवश्यक त्या ठिकाणी पाठविण्याचा विचार करीत आहे. आणि मग डेटा वापर, डेटा जेथे असतो तेथे वास्तविक बिंदू, आपणास डेटामधून मूल्य मिळेल.
आणि जुन्या दिवसांमध्ये हे सर्व एका स्वतंत्र शैलीत केले जाते, परंतु आज कदाचित हे आपल्याला माहिती असेल, विश्लेषक वातावरण असेल आणि उदाहरणार्थ त्या नंतर एक संग्रह, एक स्टोअर असेल जिथे आम्ही यापुढे डेटा ठेवत नाही. याची आवश्यकता आहे आणि शेवटी प्रक्रिया शुद्ध करणे आवश्यक आहे. या संपूर्ण डेटा लाइफ सायकलच्या व्यवस्थापनात डेटा मॉडेलिंग फिटिंग कसे दिसते?
रॉन हुईझेन्गा: हा एक चांगला प्रश्न आहे आणि एक गोष्ट आहे की मला आज येथे सर्व तपशील सांगण्याची खरोखरच वेळ नव्हती, ज्याबद्दल आपण खरोखरच बोलू लागलो आहोत ते म्हणजे डेटा वंशा. तर आम्ही जे करण्यास सक्षम आहोत ते म्हणजे आमच्याकडे आपल्या उपकरणांमध्ये डेटा वंशाची क्षमता आहे आणि जसे मी म्हणतो तसे आम्ही त्यापैकी काही प्रत्यक्षात ईटीएल साधनांमधून काढू शकतो परंतु आपण फक्त वंश रेखाटून नकाशा देखील बनवू शकता. यापैकी कोणतेही डेटा मॉडेल किंवा डेटाबेस जे आम्ही हस्तगत केले आहेत आणि मॉडेल्समध्ये आणले आहेत त्यावरून आमच्या डेटा रेषेच्या आकृतीमध्ये असलेल्या बांधकामाचा संदर्भ घेऊ शकतो.
आपण जे करण्यास सक्षम आहात ते म्हणजे डेटा स्रोत प्रवाहित करणे, जसे की आपण म्हणता, स्त्रोत ते लक्ष्य करण्यासाठी आणि डेटा संपूर्णपणे वेगवेगळ्या सिस्टममध्ये कसा प्रसारित करतो आणि आपण काय शोधणार आहात हे संपूर्ण जीवन चक्रातून, आपण कर्मचारी घेऊ. डेटा - मी वर्षांपूर्वी केलेल्या एका प्रोजेक्टवर आधारित हा माझा आवडता विषय आहे. मी एका संस्थेसह काम केले ज्याच्याकडे 30 वेगवेगळ्या प्रणालींमध्ये कर्मचारी डेटा होता. आम्ही तिथेच काय केले - आणि रेबेकाने डेटा वंशाची स्लाइड पॉप अप केली - ही एक बरीच सरलीकृत डेटा वंशाची स्लाइड आहे, परंतु आम्ही काय करू शकलो सर्व डेटा स्ट्रक्चर्स आणणे, आकृत्यामध्ये त्यांचा संदर्भ देणे आणि नंतर आम्ही दरम्यानचे प्रवाह काय आहेत हे पाहण्यास प्रत्यक्षात प्रारंभ होऊ शकतो आणि त्या भिन्न डेटा अस्तित्वांचा प्रवाहात कसा संबंध आहे? आणि आपण त्याही पलीकडे जाऊ शकतो. हा डेटा प्रवाह किंवा वंश आकृतीचा एक भाग आहे जो आपण येथे पाहतो. जर तुम्हाला त्यापलीकडे जायचे असेल तर आमच्याकडे या स्वीटचा बिझिनेस आर्किटेक्ट भाग देखील आहे आणि तिथेही तीच लागू आहे.
आम्ही डेटा मॉडेलिंगच्या वातावरणामध्ये हस्तगत केलेल्या कोणत्याही डेटा स्ट्रक्चर्सचा संदर्भ व्यवसाय मॉडेलिंग टूलमध्ये घेता येतो जेणेकरून आपल्या व्यवसायाच्या मॉडेल आकृत्या किंवा आपल्या व्यवसाय प्रक्रियेच्या आकृत्यामध्ये देखील, आपण इच्छित नसल्यास वैयक्तिक डेटा स्टोअरचा संदर्भ घेऊ शकता. डेटा मॉडेलिंग वातावरण आणि आपण आपल्या व्यवसाय प्रक्रियेच्या मॉडेलमधील फोल्डरमध्ये त्यांचा वापर करत असताना आपण त्या माहितीवर एकतर सीआरयूडी देखील निर्दिष्ट करू शकता की ती माहिती एकतर कशी वापरली किंवा तयार केली जाते आणि नंतर आम्ही व्युत्पन्न करणे सुरू करू शकतो त्यापैकी प्रभाव आणि विश्लेषण अहवाल आणि आकृत्या यासारख्या गोष्टी.
आम्ही काय मिळवायचे आमचे ध्येय आहे, आणि आमच्याकडे आधीपासूनच बर्याच क्षमता आहेत, परंतु आम्ही ज्या गोष्टींकडे पहात आहोत त्यापैकी एक म्हणजे आम्ही पहात असलेल्या गोलपोस्टसारखे आहे, जसे आपण पुढे जात असताना आपली साधने विकसित करीत आहोत, ते शेवटचे टू-अंत, संस्थात्मक डेटा वंश आणि डेटाचे संपूर्ण जीवन चक्र तयार करण्यास सक्षम आहे.
मॅल्कम चिशोलम: ठीक आहे. रेबेका, मला आणखी एक परवानगी आहे का?
रेबेका जोझवियाक: मी तुम्हाला आणखी एक परवानगी देतो, मॅल्कम, पुढे जा.
मॅल्कम चिशोलम: खूप खूप धन्यवाद. डेटा गव्हर्नन्सबद्दल विचार करणे आणि डेटा मॉडेलिंगबद्दल विचार करणे या दोन गटांना एकत्रितपणे कार्य करण्यासाठी आणि एकमेकांना समजून कसे काढावे?
एरिक लिटल: हे मनोरंजक आहे, मला वाटते की ते खरोखर संघटनेवर अवलंबून आहे, आणि माझ्या पूर्वीच्या संकल्पनेवर ते परत गेले आहे, ज्या संस्थांमध्ये पुढाकाराने व्यवसाय चालविला जात होता, तिथे आपण बरोबरच बांधले गेले होते. उदाहरणार्थ, मी डेटा आर्किटेक्चर टीमचे नेतृत्व करीत होतो पण आम्ही व्यवसाय वापरकर्त्यांशी जोडलेले होते आणि आम्ही त्यांचा डेटा गव्हर्नन्स प्रोग्राम उभे करण्यास मदत करत होतो. पुन्हा, सल्लामसलत करण्याच्या अधिक दृष्टिकोन परंतु हे खरोखर व्यवसाय कार्य आहे.
आपल्याला जे करण्यास खरोखर सक्षम असणे आवश्यक आहे ते म्हणजे आपल्याला डेटा मॉडेलर्स आणि आर्किटेक्टची आवश्यकता आहे ज्यांना खरोखर व्यवसाय समजते, व्यवसाय वापरकर्त्यांशी संबंधित असू शकतात आणि नंतर त्यास आसपासच्या कारभारासाठी उभे राहण्यास मदत केली आहे. व्यवसाय ते करू इच्छित आहे, परंतु सामान्यत: असे तंत्रज्ञान ज्ञान आहे जे आमच्याकडे अशा प्रकारचे प्रोग्राम उभे राहण्यास मदत करण्यास सक्षम असतील. हे खरोखर एक सहयोग असणे आवश्यक आहे, परंतु त्यास व्यवसायाच्या मालकीची असणे आवश्यक नाही.
मॅल्कम चिशोलम: ठीक आहे, छान आहे. धन्यवाद.
डॉ एरिक लिटल: ठीक आहे.
रेबेका जोझवियाक: ठीक आहे, खूप खूप धन्यवाद. प्रेक्षक सदस्यांनो, मला भीती आहे की आम्हाला तुमच्या प्रश्नांची उत्तरे मिळाली नाहीत, परंतु मी खात्री करुन देतो की त्यांनी आज आमच्याकडे लाइनमध्ये असलेल्या उचित अतिथीकडे जावे. एरिक, मालकॉम आणि रॉन यांचे आजचे पाहुणे म्हणून आभार मानण्याबद्दल. लोकांनो, ही छान सामग्री होती. आणि जर आपण आजच्या आयडरा वेबकास्टचा आनंद घेतला असेल तर, इंडेक्सिंग आणि ओरेक्लल्सच्या आव्हानांवर चर्चा करुन, यावे म्हणून आणखी एक आकर्षक विषय म्हणून, आपण सामील होऊ इच्छित असल्यास आयडेरा देखील पुढच्या बुधवारी हॉट टेक्नॉलॉजीजवर जात आहे.
धन्यवाद, लोकांनो, काळजी घ्या आणि आम्ही पुढच्या वेळी आपल्याला भेटू. बाय बाय.